目次
- 動的配列クラス std::vector とは
- データ構造
- 準備:インクルード
- 宣言・初期化
- vector への代入
- 値の参照、代入
- データの追加
- データの削除
- その他のメンバ関数
- その他
- アルゴリズム
- 参考
- リファレンス
- コンストラクタ
- accumulate()
- assign() : T&
- at(int ix) : T&
- back() : T&
- begin() : vector<T>::iterator
- capacity() : size_t
- clear() : void
- count()
- emplace_back() : void
- empty() : bool
- end() : iterator
- erase(iterator) : iterator
- find(first, last, v) : iterator
- front() : T&
- insert(iterator, const T&) : iterator
- pop_back() : void
- push_back(const T&) : void
- reserve(size_t) : void
- resize(size_t, T = T()) : void
- revese()
- shrink_to_fit() : void
- size() : size_t
- sort()
- swap(vector<T> &) : void
- フィードバック
動的配列クラス std::vector とは
std::vector とは C++ で標準に使用できるとっても便利な動的配列クラスでござるぞ。
通常配列と同じように [] 演算子で値を参照・代入することはもちろん、サイズ情報等の取得やデータの挿入削除なども可能だ。
「動的配列」とは配列サイズを自由に増減できるという意味。「可変長配列」と呼ばれることもある。
通常の配列は非常に便利で使用頻度の高いデータ構造だが、サイズを予め指定する必要があり、実行時に動的にサイズを変更することが出来ない。
例えば、「int data[100]; 」と宣言した場合、実行時にデータ数が100を超えるとお手上げだ。
スネークゲームでは、ヘビの胴体の長さがどんどん長くなるので、
胴体座標を動的配列で実装している。
これを普通の配列で実装すると、胴体の最大長を保持する可能性があるので、78*21=1638 のサイズの配列をあらかじめ確保しておく必要がある。
この程度のサイズであれば、予め最大サイズを確保してもたいした問題ではないが、スマートな方法とは言えない。
それより、動的配列を使い、胴体が伸びたときに配列を動的に大きくするほうがずっとスマートである。
C++ には vector 以外にも、複数のデータを取り扱うためのクラス(例:std::list、 これらを コンテナクラス と呼ぶ) がいくつか用意されているが、 vector は、最も単純で(少ないデータ数では)高速で、メモリ効率も良く、扱いやすく、最も使用頻度の高いクラスなんだぞ。
というわけで、vector は C++ では必須のアイテムなので、ちゃんと理解し、増減するデータをスマートに取り扱う方法をマスターしてほしい。
データ構造
std::vector のデータ構造の例を下図に示す。
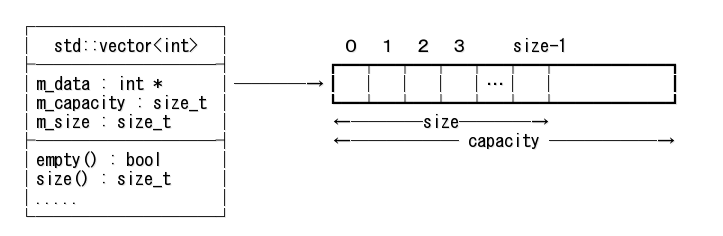
配列要素を格納する領域を動的に確保し、m_data がそのアドレスを指している。 その容量と中に入っている要素数をメンバ変数 m_capacity, m_size で保持している。
これはデータ構造の一例であり、あなたの環境の実際のデータ構造とは少し違うかもしれない。
サイズ、キャパシティの値を保持せず、データエリア末尾へのポインタを持つ実装もある。
重要なことは、データ領域が連続していることと、末尾に予備の領域を持つ、ということである。
データ領域が連続しているので、インデックスにより要素を高速に参照することができるし、
ポインタ引数を要求する関数引数に指定することもできる。
末尾に予備の領域を持つので、要素が増えた時に領域を再アロケートしないですむ場合がある、ということだ。
準備:インクルード
まずは、vector を使うための準備について説明する。
vector は C++標準のライブラリであり、「#include <vector>」を記述することで利用可能になる。
名前空間は「std」なので、使用の度に「std::」を前置するか、または「using namespace std;」を記述しておく。
#include <vector> // ヘッダファイルインクルード
int main()
{
std::vector<int> v; // ローカル変数として、v を生成
.....
}
#include <vector> // ヘッダファイルインクルード
using namespace std; // 名前空間指定
int main()
{
vector<int> v; // ローカル変数として、v を生成
.....
}
宣言・初期化
vector オブジェクトを宣言するには、空vectorを宣言する、サイズを指定して宣言する、サイズと全てのデータを指定して宣言する、 元データを指定して宣言する、他のオブジェクトを元にして宣言する、のようにいくつもの方法がある。 本章ではそれらの方法を順次解説する。
ローカル変数またはグローバル変数として vector オブジェクトを宣言すると、オブジェクトが生成され利用可能になる。
これらはスコープを外れると自動的に破棄される。
通常のクラスなので new で生成し、delete で破棄することも可能だ。
単純な宣言
std::vector オブジェクトを生成するには「std::vector<型> オブジェクト名;」 と記述する。
オブジェクト名とは、宣言する動的配列を識別するための名前のことだ。変数名と言ってもよい。
vector はクラスなので、それを実体化したものはオブジェクトまたはインスタンスと呼ばれる。
下記は、int 型の動的配列 data を宣言している例だ。
std::vector<int> data; // int 型の動的配列 data の宣言
当然、型の部分はどんな型でも構わない。char や double や、自分で定義した構造体、クラスでもOKだ。
※ ただし、初期化時にデフォルトコンストラクタ、バッファ拡張時にコピーコンストラクタが呼ばれことがあるので、
それらがちゃんと定義されている必要がある。
また、vector などのコンテナクラスを指定することも出来る(参照:2次元配列)。
通常の配列宣言の「型 配列名[要素数];」とはちょっと順序が違うが、似たような感じだ。
「std::vector<型> オブジェクト名;」には要素数の指定が無いじゃないかと気づいた人は観察力がある。要素数の指定方法は次節で説明する。
このようにして宣言したオブジェクトの要素数は0だ。データを追加するには次の章で説明する push_back() などを使う。
< > は何だ?と思う人もいるかもしれない。これはC++のテンプレートという機能を使うための記法だ。
テンプレートを完全に理解するのは難易度が高いので、深く理解しようとすると先に進めなくなる。
深入りはせず、現在のところはこういう書き方をすると覚えてほしい。
要素数を指定した宣言
動的配列は後でサイズを増減させることが出来るが、データ領域の確保・破棄とデータのコピー処理を伴う場合があり、若干の処理時間を要する。
なので、最初の要素数が分かっている場合は、要素数を指定してオブジェクトを作るようにした方がよい。
構文は「std::vector<型> オブジェクト名(要素数);」だ。
std::vector<int> data(123); // int 型で、初期要素数 123 の動的配列 data の宣言
配列では要素数を「[要素数]」で指定するが、vector では「(要素数)」で指定する。実はこれ、コンストラクタの引数なのである。
要素の初期化
要素数を指定するだけでなく、全要素の値を指定して初期化することも可能だ。
「std::vector<型> オブジェクト名(要素数, 値);」と記述すると、指定された数の要素を確保し、全ての要素を指定された値で初期化する。
std::vector<int> data(10, 5); // 要素数10、全ての要素の値5 で初期化
上記の方法では、値が全て同じ場合でないと初期化できない。
「std::vector<型> オブジェクト名(型* first, 型* last);」と記述すると、first から last が指す先までのデータで動的配列を初期化する。
厳密に言うと、last は最後の元データの次を指す。[first, last) の範囲を元に、動的配列を初期化する。
通常配列でデータを指定し、それを元に動的配列を構築し初期化出来る。
int org_data[] = {4, 6, 5}; // 元データ
std::vector<int> data(org_data, org_data + 3); // 元データから動的配列を生成
配列末尾へのポインタは org_data + 3 と記述しているが、データ配列サイズが変わった時に、修正しなくてはならないので、危険だ。
C++0x(VS2010以上)で std::end(配列名) という関数が追加され、配列末尾へのポインタを返してくれるようになった。
これを使えば、上記は下記のように記述することが出来る。
int org_data[] = {4, 6, 5}; // 元データ
std::vector<int> data(org_data, std::end(org_data)); // 元データから動的配列を生成
実は上記の記述方法は古い書き方で、C++11(VS2013以上)から vector の初期化で初期値を直接指定可能になった。
「std::vector<型> オブジェクト名{値0, 値1, 値2, ... 値N-1};」と記述できる。
std::vector<int> data{4, 6, 5}; // データ列を指定して動的配列を生成
こちらの方法の方が直感的で分かりやすく、行数も短い。C++11 が利用可能であれば、この記法を使うことを強く薦める。
※ ちなみに、「std::vector<型> オブジェクト名 = {値0, 値1, 値2, ... 値N-1};」と書いてもよい。
コピーコンストラクタ
コピーコンストラクタとは、同じ型のオブジェクトを渡され、それと同じ内容のオブジェクトを生成するコンストラクタのことである。
「std::vector<型> オブジェクト名(コピー元オブジェクト名);」と記述する。
当然ながら、コピー元オブジェクトと生成するオブジェクトは通常同じ型である。
※ 暗黙の型変換が可能な型であれば、コピー元オブジェクトとして指定可能ではある。
std::vector<int> org{1, 2, 3};
std::vector<int> x(org); // コピーコンストラクタ
上記のコードは org をコピーするので {1, 2, 3} という値をもつ動的配列 x を生成する。
2次元配列
「std::vector<std::vector<型>> オブジェクト名;」の様に、vector を入れ子にすることで、2次元以上の配列を宣言できる。
2次元配列は、C++11 であれば、以下の様に通常配列と同じ様に初期化することが可能。
std::vector<std::vector<int>> vv{{1, 2, 3}, {4, 5, 6}};
※ 「>>」は右シフト演算子なので、C++11未満では「> >」と、間に空白を入れる必要があった。 Visual Studio では VS2010 から「>>」をサポートしている。
このようにして生成した2次元配列は、vv[x][y] の様に、普通の多次元配列と同様にアクセスできる。
もっと入れ子を深くすれば、3次元や4次元も可能である。
演習問題:
- char 型の動的配列 str を宣言しなさい。
- 要素数3の double 型の動的配列 pos を宣言しなさい。
- char 型、値 'a'、要素数10の動的配列 a を宣言するコードをビルドし、デバッガで中身を確認しなさい。
- double 型、1.1, 2.2, 3.3, 4.4 の4つの値をもつ動的配列 d を宣言するコードをビルドし、デバッガで中身を確認しなさい。。
- コピーコンストラクタのサンプルコードをビルドし、デバッガで正しくコピーされていることを確認しなさい。
- vector<int> v1(5); vector<int> v2{5}; vector<int> v3[5]; それぞれの意味を答えなさい。 念の為にビルドしてデバッガで中身を確認しなさい。
std::vector<char> str;
std::vector<double> pos(3);
std::vector<char> a(10, 'a');
std::vector<double> d{1.1, 2.2, 3.3, 4.4};
std::vector<int> org{1, 2, 3};
std::vector<int> x(org); // コピーコンストラクタ
vector<int> v1(5); // 総素数 5 の vector
vector<int> v2{5}; // 要素数は 1 で、値は 5
vector<int> v3[5]; // 要素数 0 の vector * 5個の配列
まとめ:
- vector<型> オブジェクト名; で型の動的配列オブジェクトを生成
- vector<型> オブジェクト名(要素数); で要素数を指定
- vector<型> オブジェクト名(要素数, 値); で全ての要素を 値 で初期化
- vector<型> オブジェクト名{値, 値, 値, ...値}; で全ての要素を初期化(ただしC++11以上)
- vector<型> オブジェクト名(コピー元オブジェクト); でオブジェクトをコピー
- vector<vector<型>> オブジェクト名; で2次元配列を生成
vector への代入
現在保持している要素を全て破棄し、新しい要素を代入することが出来る。
operator=(const vector<T>&) : vector<T>&
同じ型の vector どうしであれば、= 演算子を使って、通常の変数同様に代入することが出来る。
vector<int> a{1, 2, 3, 4};
vector<int> b{9, 8};
b = a; // a の内容を b に代入
= 演算子は代入されたものへの参照を返すので、通常の式と同じように、= を連続させることも可能だ。
vector<int> a{1, 2, 3, 4};
vector<int> b, c;
c = b = a; // a の内容を b, c に代入
assign(first, last) : void
assign(first, last) により[first, last) の範囲のデータを vector に代入することができる。
以下は、配列のデータの一部を vector に代入する例だ。
int ar[] = {1, 2, 3, 4, 5, 6, 7};
vector<int> v{9, 8};
v.assign(&ar[0], &ar[3]); // v の内容は {1, 2, 3} になる
assign(size_t n, const T& val) : void
要素数、値を指定して代入することもできる。
resize(size_t n, const T& val) でもある意味似たようなことが可能だが、resize() は元からあった要素を必ず消すわけではないので、
特定の値で初期化したい場合は、この assign(n, val) を使うのが便利だ。
vector<int> v{9, 8};
v.assign(3, 1); // v の内容は {1, 1, 1} になる
値の参照、代入
operator[](int ix) : T&
[] 演算子(operator[](int)) を使って、普通の配列と同じように、インデックスを指定しての配列要素値の参照・代入が可能。
operator[](int) と聞くと身構える人がいるかもしれないが、「data[10]」の様に、普通の配列の要素にアクセスする時と同じ記述だ。
恐れることは何も無い。
[] 演算子を使ったランダム・アクセスの所要時間は O(1) だ。これは通常配列同様に非常に高速ということだ。
下記は、配列要素値の参照と代入例。普通の配列要素の参照・代入とまったく同じでしょ。
std::vector<int> data{3, 1, 4, 1, 5, 9, 2, 6, 5, 3};
for (int i = 0; i < 10; ++i)
std::cout << data[i]; // data の i 番目の要素を表示
const int SZ = 10; // 要素数
std::vector<int>v(SZ); // 指定要素数で、vector を生成
for(int i = 0; i < SZ; ++i)
v[i] = i; // 要素を 0, 1, 2, 3, ... 9 に設定
VC++ の場合、動的配列の範囲外のデータをアクセスすると、デバッグモードであればアサーション例外が発生する。
リリースモードでは通常配列と同じように範囲外の部分を何事も無かったかのようにアクセスする。
C/C++ の配列は高速性を優先するために、添字の範囲チェックを行わない。
それが元で原因不明のバグに悩まされることもままある。
vector を使い、デバッグモードでテストをするようにすれば、そのようなバグはたちどころに発見することができるぞ。
普通の配列同様、「int *ptr = &v[0];」の様に記述することで要素へのポインタを取得することが出来、
ポインタ経由で要素を参照・修正することが出来る。
これは、vector の要素は連続する領域に格納されていることが保証されているからだ。
後で説明する v.data() でデータ領域先頭アドレスを取得することもできる。&v[0] と書くのと等価だ。
at(int ix) : T&
[] 演算子(operator[](int ix))だけでなく at(int ix) で ix 番目のデータにアクセスすることも可能です。
at(int ix) は値ではなく要素への参照を返すので、[] 演算子同様、下記の様に、値を参照することも代入することも可能です。
[] 演算子(ix) と at(int ix) の違いは、リリースモードにおいて前者がインデックス(ix)の範囲チェックを行わないのに対し、
後者は範囲チェックを行い、範囲外であれば例外を発行する点だ。その分すこーし低速になるが、安全性が向上するぞ。
std::vector<int> data{3, 1, 4, 1, 5, 9, 2, 6, 5, 3};
for (int i = 0; i < 10; ++i)
std::cout << data.at(i); // data の i 番目の要素を表示
const int SZ = 10; // 要素数
std::vector<int>v(SZ); // 指定要素数で、vector を生成
for(int i = 0; i < SZ; ++i)
v.at(i) = i; // 要素を 0, 1, 2, 3, ... 9 に設定
イテレータ
vector, list, map 等のコンテナクラスにはイテレータというものが用意されている。
イテレータとは抽象化されたポインタのことである。
イテレータはコンテナの要素を指し、*演算子でイテレータが指す要素を参照・変更することができ、
インクリメント・デクリメントで次・前の要素に移動することができる。
vector<T> のイテレータの型は vector<T>::iterator である。ちなみに list であれば list<T>::iterator だ。
std::vector<int>::iterator itr; // vector<int> の要素へのイテレータ
begin() は最初の要素への、end() は最後の要素の次へのイテレータを返す。 これらを使って、イテレータを初期化し、イテレータを介して要素を参照・変更する。
std::vector<int> v{1, 2, 3, 4};
std::vector<int>::iterator itr = v.begin(); // 最初の要素を指すイテレータ
std::cout << *itr << "\n"; // 最初の要素の値を表示
++itr; // 次の要素に移動
*itr = 9; // 二番めの要素の値を 9 に変更
std::vector<int>::iterator とタイプするのは面倒なので、通常は型推論の auto を使用する。
std::vector<int> v{1, 2, 3, 4};
v に要素を格納;
auto itr = v.begin(); // 最初の要素を指すイテレータ
イテレータを使って、vector v の要素を全て走査するには以下のように記述する。
for(auto itr = v.begin(); itr != v.end(); ++itr) {
*itr でイテレータの指す要素を参照
}
vector の場合、イテレータとポインタは同一の型ではないが、特徴・機能は同じである。なので、通常はイテレータを使う必然性は無いのだが、
イテレータを使って記述しておくと、後でクラスを list に変えてもほとんどコード修正の必要が無くなる場合がある。
すなわち変更に強いコードになる場合があるわけだ。
だが、イテレータを使えば完全にコンテナクラスに依存しないように書けるというのは幻想である、と偉い人も言っているので、過信は危険だ。
演習問題:
- int型で、100個の要素を持つ動的配列を作り、各要素を [0, 99] の範囲の乱数で満たすコードを書きなさい。
- 上記で生成した配列の中身を全て表示するコードを書きなさい。
- int 型で 10個の要素を持つ動的配列 v を宣言し、v[20] の値を表示するコードを記述し、デバッグモードとリリースモードで実行してみなさい。
- ついでに、通常配列で同様のことを行うと、どうなるかを確認しなさい。
std::vector<int> v(100);
for(int i = 0; i < 100; ++i)
v[i] = rand() % 100;
for(int i = 0; i < 100; ++i)
std::cout << v[i] << "\n";
std::vector<int> v(10);
std::cout << v[20] << "\n";
int v[10];
std::cout << v[20] << "\n";
まとめ:
- 通常の配列と同じように [] 演算子が使用可能
- v[i] で i 番目(0 オリジン)の要素を参照可能
データの追加
- push_back() : void
- emplace_back(コンストラクタ引数) : void
- insert(iterator, 値) : iterator
push_back() : void
データを末尾に追加するには push_back(d); を使う。
std::vector<int> v; // 空の動的配列を生成
v.push_back(123); // 末尾に 123 を追加
処理時間は O(1) で高速。O(式) は処理時間を表す数学的な記法。「ビッグ・オー記法」と呼ばれる。
O(1) は配列要素数に依らず常に一定時間で処理出来るという意味で、高速なのだ。
通常、データの追加はこのメンバ関数のみを使用する。
※ 細かいことを言うと、push_back(値) が呼ばれたとき、既に確保したメモリに空きがない場合は、
メモリを再アロケート、データをコピー、以前のメモリを破棄、という処理が行われる。
これはデータ数が多い場合は結構重い処理なのだが、配列サイズが 0 から N になるまで push_back() を繰り返しても、
log N / log 2 回(または log N / log 1.5回)しか行われない。
なので厳密には O(1) ではないのだが、実質的には O(1) と理解しておいてよい。
emplace_back(コンストラクタ引数) : void
コンテナが保持する型Tがクラスの場合、新規クラスオブジェクトをコンテナ末尾に追加するには、下記のように記述する。
v.push_back(T(コンストラクタ引数));
こう書くと、push_back コール時にクラスTのコンストラクタが呼ばれ、オブジェクトが生成される。
そして、push_back() の中で、コピーコンストラクタに渡されて生成されたオブジェクトがコンテナに追加され、push_back() コール時に生成されたオブジェクトは破棄される。
コピーコンストラクタ、オブジェクト破棄の処理が重いクラスの場合、このような無駄な処理はパフォーマンス低下を招く場合がある。
そこで C++11 で導入されたのが emplace_back() だ。
引数にコンテナが保持するクラスのコンストラクタ引数を指定すると、余分なテンポラリオブジェクトを生成することなく(生成しないので当然破棄することもなく)
オブジェクトを生成し、コンテナの最後に追加してくれるぞ。
例えば、コンストラクタが文字列と整数を引数にとるクラス Hoge がある場合、末尾にデータを追加する処理は以下のように記述出来る。
class Hoge {
public:
Hoge(std::string&, int); // コンストラクタ
.....
};
.....
std::vector<Hoge> v;
v.emplace_back("abc", 123); // push_back(Hoge("abc", 123)) と同意
insert(iterator, 値) : iterator
なにがなんでも任意の場所にデータを挿入したい場合は insert(iterator, 値) を使う。
insert(iterator, 値) は、第1引数に挿入する場所へのイテレータを、第2引数に挿入するデータを指定する。
イテレータとは抽象化されたポインタのこと。ちゃんとした説明は長くなるし、初級者には理解が大変なのでここでは省略する。
i 番目に挿入したい場合は「オブジェクト名.begin() + i」と書くと覚えて欲しい。
std::vector<int> v(10, 3); // 値が3,個数10個
v.insert(v.begin() + 4, 7); // [4] の位置に 7 を挿入
// 結果は {3, 3, 3, 3, 7, 3, 3, 3, 3, 3, 3} となる
※ 個人的には insert(size_t index, 値) というメンバ関数があってもよいと考えるが、何故無いのだろう?
insert() の処理時間は O(N) 。O(N) とは配列要素数に比例して処理時間を要するという意味。
データ数が100倍になると、処理時間も100倍になる。
データをずらす処理を行う必要があるので、その分処理時間を食うというわけだ。
それに対して push_back() は O(1) なので、データ数がいくら増えても常に一定時間で処理が終わる。
データ列の途中に頻繁に挿入・削除を行うのであれば std::list や、ギャップベクターなど他のコンテナクラスの使用を検討すべき。
データ列の先頭にのみ頻繁に挿入・削除を行うのであれば std::deque がお薦め
(実際、スネークゲームでは、胴体座標の管理に std::deque を使用している)である。
ただし、データ数が少ない(数10個程度)場合であれば、vector は十分高速なので、処理時間は問題にはならない。
そんな場合は vector を使用すべきである。
演習問題:
- 空の int型 vector オブジェクトを生成し、末尾に 1 ~ 10 のデータを追加するコードを書きなさい。
- 初期値 0 で、10個の int型 vector オブジェクトを生成し、[5] の位置に 7 を挿入するコードを書きなさい。
std::vector<int> v;
for(int i = 1; i <= 10; ++i)
v.push_back(i);
std::vector<int> v(10, 0);
v.insert(v.begin() + 5, 7);
まとめ:
- オブジェクト.push_back(値) で末尾に値を追加
- オブジェクト.emplace_back(コンストラクタ引数) で末尾に値を追加
- オブジェクト.insert(イテレータ, 値) で任意の位置に値を挿入可能
- ただし insert() 処理時間は O(N) なので、要素数が膨大な場合は注意
データの削除
- pop_back() : void
- erase(iterator) : iterator
- erase(first, last) : iterator
pop_back() : void
最後の要素を削除したい場合は pop_back() を用いる。
std::vector<int> v{3, 1, 4, 1, 5};
v.pop_back(); // 末尾データ(この場合は 5)を削除
pop_back() も push_back() 同様、処理時間は O(1) と高速である。
空の vector に対して、pop_back() を実行するとデバッグモードでは例外が発生する。
リリースモードでは内容が不正になるようだ(VS2013)。
次の章で説明する empty() または size() で vector が空でないことを確認するようにした方がよい。
pop_back() は何故か void 型で、削除した値を返さない。 なので、最後の要素の値を取り出して削除したい場合は、後で説明する back() を使用する。
std::vector<int> v{3, 1, 4, 1, 5};
int last = v.back(); // 末尾データを取り出しておく
v.pop_back(); // 末尾データ(この場合は 5)を削除
erase(iterator) : iterator
任意の位置の要素を削除したい場合は erase(iterator) を使用する。
std::vector<int> v{3, 1, 9, 4};
v.erase(v.begin() + 2); // 3番目の要素(9)を削除
erase() で途中の要素を削除すると、サイズが一つ減り、削除された要素以降のデータがひとつずつ前に移動される。
※ 要素数が膨大な場合、データをずらすにはそれなりの時間が必要なので、注意すること。
イテレータは前節で言及したように、削除する要素位置を示すもので、i 番目の要素は「オブジェクト名.begin() + i」で指定する。
erase(first, last) : iterator
vector の一部である [first, last) を削除する場合、その間の要素をひとつづつ erase(iterator) で消さなくても、erase(first, last) で一度に削除することができるぞ。
削除の処理時間は O(N) なので、M文字を削除するのにループを使うと O(N*M) になってしまうが、erase(first, last) を使えば O(N) で済むぞ。
下記は、v の2, 3番目の要素を一度に削除する例だ。
std::vector<int> v{3, 1, 4, 1, 5};
v.erase(v.begin() + 1, v.begin() + 3); // 1, 4 を削除
演習問題:
- pop_back() で末尾を削除するコードを書き、デバッガで実行し、末尾データが削除されたことを確認しなさい。
- erase() で途中の要素を削除し、本当に削除されたことを確認するコードを書き、実行してみなさい。
- int 型の vector を {1, 2, 3, 4, 5, 6, 7, 8, 9, 10} で初期化し、3 から 8 までを erase(first, last) を使って削除しなさい。
std::vector<int> v{3, 1, 4, 1};
v.pop_back();
std::vector<int> v{3, 1, 4, 1};
v.erase(v.begin() + 2); // 4 を削除
for(int i = 0; i != v.size(); ++i) {
std::cout << v[i] << "\n";
}
std::vector<int> v{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
v.erase(v.begin() + 2, v.begin() + 8);
まとめ:
- オブジェクト.pop_back() で末尾要素を削除
- オブジェクト.erase(イテレータ) で任意位置の要素を削除
- ただし処理時間は O(N) なので、要素数が膨大な場合は注意
その他のメンバ関数
ここまで、動的配列の宣言、値の参照・代入・追加・削除方法について説明した。
それらを使えば通常配列を動的配列に置き換えることができるはずだ。
実は動的配列には上記以外にも便利な機能がメンバ関数としていくつも用意されている。
配列が空かどうかをチェックしたり、要素数を調べたり、サイズを変更することもできる。
これらは通常配列に対する明らかなアドバンテージである。
vector の状態を取得
- empty() : bool
- size() : size_t
- capacity() : size_t
empty() : bool
「bool empty()」は動的配列が空かどうかを判定する関数。空ならば true を、空でなければ false を返す。
次に出てくる size() を使って、size() == 0 と判定するのと同等だ。
が、コンテナクラスによっては size() 計算よりも empty() の方が高速な場合がある。
なので、vector などのコンテナクラスに対しては empty() を使うことが推奨されている。
if( !v.empty() ) {
// v が空でなければ、なんらかの処理を行う
}
size() : size_t
「size_t size()」は、要素数を返す関数。
通常配列だと「sizeof(data)/sizeof(data[0])」のように記述しないと、要素数を取得できないが、
vector であれば「data.size()」と簡潔かつ分かりやすく書ける。
※ size_t はサイズを表す型で、符号なし整数の組み込み型である。ちなみに、sizeof() も size_t 型を返す。
for(int i = 0; i != v.size(); ++i) { // 全要素に対するループ
.....
}
capacity() : size_t
「size_t capacity()」は、動的配列が確保しているメモリに入る要素数、すなわち現在のデータ領域容量を返す関数。
vector は実際の要素数より若干大目にメモリを確保している。これは要素が増えた時、常にメモリを再確保するのではなく、
余裕を持たせておくことで、頻繁なメモリ確保とデータのコピーを避けるためだ
(参照:動的配列クラス 演習問題の図)。
vector の要素を取得
- front() : 要素の型への参照
- back() : 要素の型への参照
- data() : 要素の型へのポインタ
front() : 要素の型への参照、back() : 要素の型への参照
「front()」は先頭要素を返す関数。「オブジェクト名[0]」と記述するのと同等。
「back()」は末尾要素を返す関数。「オブジェクト名[オブジェクト名.size() - 1]」と記述するのと同等。
front() はあまりありがたみが無いが、back() はタイプ数が大幅に減るし、分かりやすいので存在価値が高いぞ。
if( !v.empty() ) {
auto f = v.front(); // 最初の要素
auto b = v.back(); // 最後の要素
...
}
front(), back() ともに、値を返すのではなく、最初・最後の要素への参照を返すので、最初・最後の要素へ代入することも出来るぞ。
std::vector<int> v{1, 2, 3, 4};
v.front() = 11; // 最初の要素を 11 に変更
v.back() = 44; // 最後の要素を 44 に変更
data() : 要素の型へのポインタ
「data()」は配列データ先頭アドレスを返す関数。「&オブジェクト名[0]」と記述するのと同等。
vector は通常配列と同じようにデータ領域が連続したアドレスだということが保証されている。
なので、データアドレスを他の関数に渡して処理することも可能だ。
vector の状態を変更
- clear() : void
- resize(サイズ) : void
- reserve(サイズ) : void
- swap(オブジェクト) : void
- shrink_to_fit() : void
clear() : void
「clear()」は動的配列を空にする関数。
サイズを0にするだけ。メモリが解放されるわけではない。
メモリを解放したい場合は後で説明する shrink_to_fit() または swap() イディオムを使用する。
resize(サイズ) : void
「resize(size_t sz)」は要素数を指定サイズに設定する関数。
sz が現在のキャパシティを超えていれば、メモリがアロケートされ,データがコピーされる。
サイズが増えた部分の値を指定したい場合は、「resize(size_t sz, 値)」と、第2引数で値を指定する。
サイズが減っても、その分のメモリが解放されるわけではない。
不要になったメモリを解放したい場合は後で説明する shrink_to_fit() または swap() イディオムを使用する。
reserve(サイズ) : void
「reserve(size_t sz)」はキャパシティを指定する関数。
データを大量に追加する場合、メモリのアロケートとデータコピーが多く呼ばれる場合がある。
そうなるとパフォーマンスが低下する場合があるので、追加するデータの数が予めわかっていれば、reserve() でメモリを確保する方がパフォーマンス的に好ましい。
std::vector<int> v;
v.reserve(10000); // 予め1万個分の領域を確保しておいた方が高速
for(int i = 0; i < 10000; ++i)
v.push_back(i);
swap(オブジェクト) : void
「swap(オブジェクト)」は引数で指定されたオブジェクトと内容を入れ替える関数。
std::vector<int> v, z;
v, z にデータを追加
v.swap(z); // v と z の内容を入れ替える
shrink_to_fit() : void
先に書いたように、clear() を行ってもメモリは解放されないので、C++11以前では以下のようなコードが使用されていた。
std::vector<int> v;
v にデータを追加;
std::vector<int>().swap(v); // 空のテンポラリオブジェクトを生成し、中身を入れ替える
「shrink_to_fit()」は、C++11 で追加された関数で、キャパシティを現在のサイズの値にし、余分なメモリを解放する関数。
C++11以前では、shrink_to_fit() がなかったので以下のようなイディオムが使用されていた。
std::vector<int> v;
v にデータを追加;
std::vector<int>(v).swap(v); // v をコピーしたテンポラリオブジェクトを生成し、中身を入れ替える
イテレータ
begin() : イテレータ
ベクターの最初の要素へのイテレータを返す。
end() : イテレータ
ベクターの最後の要素の次へのイテレータを返す。
全要素をイテレータで走査する場合、以下のように記述する。
std::vector<int> v{3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5};
for(auto itr = v.begin(); itr != v.end(); ++itr) {
*itr により要素を参照・変更
}
cbegin() : const イテレータ
ベクターの最初の要素への const なイテレータを返す。
cend() : const イテレータ
ベクターの最後の要素の次への const なイテレータを返す。
全要素をイテレータで走査する場合、以下のように記述する。
std::vector<int> v{3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5};
for(auto itr = v.cbegin(); itr != v.cend(); ++itr) {
*itr により要素を参照; // const なので要素を修正不可
}
演習問題:
- std::vector<int> v; に対して、empty(), size(), capacity() をコールし、それぞれの値を表示するコードを書きなさい。
- std::vector<int> v{3, 1, 4}; に対して、empty(), size(), capacity() をコールし、それぞれの値を表示するコードを書きなさい。
- std::vector<int> v{3, 1, 4}; に対して、front(), back() をコールし、それぞれの値を表示するコードを書きなさい。
- std::vector<int> v{3, 1, 4}; に対して、data() をコールし、返されたアドレスの内容を確認しなさい。
- std::vector<int> v{3, 1, 4}; に対して、clear() をコールし、empty(), size(), capacity() の値を表示するコードを書きなさい。
- std::vector<int> v{3, 1, 4}; に対して、resize(8) をコールし、empty(), size(), capacity()、各要素の値を表示するコードを書きなさい。
- std::vector<int> v{3, 1, 4}; に対して、resize(1) をコールし、empty(), size(), capacity()、各要素の値を表示するコードを書きなさい。
- std::vector<int> v{3, 1, 4}; に対して、reserve(8) をコールし、empty(), size(), capacity()、各要素の値を表示するコードを書きなさい。
- std::vector<int> v{3, 1, 4}; に対して、reserve(1) をコールし、empty(), size(), capacity()、各要素の値を表示するコードを書きなさい。
- std::vector<int> v{3, 1, 4}; に対して、resize(1); shrink_to_fit() をコールし、empty(), size(), capacity()、各要素の値を表示するコードを書きなさい。
- std::vector<int> v{3, 1, 4}, z{8, 9}; に対して、v.swap(z); を実行し、それぞれの内容を表示するコードを書きなさい。
- C++11のデータ列挙型初期化子を使用せず、{{1, 2, 3}, {4, 5, 6}} という初期値を持つ2次元配列を構築しなさい。
std::vector<int> v;
cout << v.empty() << "\n";
cout << v.size() << "\n";
cout << v.capacity() << "\n";
std::vector<int> v{3, 1, 4};
cout << v.empty() << "\n";
cout << v.size() << "\n";
cout << v.capacity() << "\n";
std::vector<int> v{3, 1, 4};
cout << v.front() << "\n";
cout << v.back() << "\n";
std::vector<int> v{3, 1, 4};
int *ptr = v.data();
std::vector<int> v{3, 1, 4};
v.clear();
cout << v.empty() << "\n";
cout << v.size() << "\n";
cout << v.capacity() << "\n";
std::vector<int> v{3, 1, 4};
v.resize(8);
cout << v.empty() << "\n";
cout << v.size() << "\n";
cout << v.capacity() << "\n";
std::vector<int> v{3, 1, 4};
v.resize(1);
cout << v.empty() << "\n";
cout << v.size() << "\n";
cout << v.capacity() << "\n";
std::vector<int> v{3, 1, 4};
v.reserve(8);
cout << v.empty() << "\n";
cout << v.size() << "\n";
cout << v.capacity() << "\n";
std::vector<int> v{3, 1, 4};
v.reserve(1);
cout << v.empty() << "\n";
cout << v.size() << "\n";
cout << v.capacity() << "\n";
std::vector<int> v{3, 1, 4};
v.resize(1);
cout << v.empty() << "\n";
cout << v.size() << "\n";
cout << v.capacity() << "\n";
v.shrink_to_fit();
cout << v.empty() << "\n";
cout << v.size() << "\n";
cout << v.capacity() << "\n";
std::vector<int> v{3, 1, 4};
std::vector<int> z{8, 9};
v.swap(z);
for(int i = 0; i < (int)v.size(); ++i)
std::cout << v[i] << "\n";
for(int i = 0; i < (int)z.size(); ++i)
std::cout << z[i] << "\n";
int dd[][3] = {{1, 2, 3}, {4, 5, 6}};
std::vector<std::vector<int>> vv;
vv.push_back(std::vector<int>(dd[0], std::end(dd[0])));
vv.push_back(std::vector<int>(dd[1], std::end(dd[1])));
まとめ:
- オブジェクト.empty() で要素が空かどうかを判定
- オブジェクト.size() で要素数を取得
- オブジェクト.capacity() でメモリ確保済み要素数を取得
- オブジェクト.front() で最初の要素を取得
- オブジェクト.back() で最後の要素を取得
- オブジェクト.data() で要素格納領域アドレスを取得
- オブジェクト.clear() で要素を空にする。メモリの解放は行われない。
- clear() 後にメモリ解放を行い対場合は、オブジェクト.shrink_to_fit() をコール
- オブジェクト.resize(SZ) で、要素数を指定
- オブジェクト.reserve(SZ) で、キャパシティを指定
- オブジェクト.swap(オブジェクト2) で、オブジェクト、オブジェクト2 の要素を全交換
その他
vector を関数の引数として渡す
vector はクラスなので、vector オブジェクトを引数として関数に渡すことが可能です。
例えば、下記の様に vector<int> を引数とし、要素の最大値を返す関数を定義することが出来ます。
int max(std::vector<int> v)
{
int maxVal = INT_MIN; // 整数最小値
for(int i = 0; i < (int)v.size(); ++i) {
if( v[i] > maxVal )
maxVal = v[i];
}
return maxVal;
}
int main()
{
std::vector<int> v;
v に要素を追加;
int mx = max(v);
.....
}
上記関数は正しく動作するのですが、引数の型が実体になっているので、関数コール時にコピーコンストラクタが呼ばれて、
コピーされたオブジェクトが関数に渡されます。
要素数が多い場合、コピーコンストラクタの処理はそれなりに重くなります。
なので、コピーする必然性がなければ、実体ではなく参照渡しにするのが普通です。
int max(std::vector<int> &v)
{
..... // 中身はいっしょ
}
こうしておけば、関数に渡されるのはオブジェクトのアドレスなので、処理時間を要することはありません。
さらに言えば、この場合は、関数の中で配列要素を修正しないので、const std::vector<int> &v とした方がよいです。
当然ながら、関数内で要素を修正する場合は、const を付けないようにします。
このように、std::vector は簡潔な表記で、関数の引数としてオブジェクトを渡すことが可能です。
それに比べ通常配列だと、サイズ情報を保持していないので、引数に要素数または最後のアドレスを指定する必要があります。
この点も std::vector が優れているところです。
配列要素のアドレス取得
vector<型> オブジェクト v の ix 番目の要素のアドレスを取得したい場合は、通常配列と同じ用に &v[ix] と書きます。
型は vector が保持する要素の型へのポインタとなります。
std::vector<int> v(10); // 要素数10個の配列
int *ptr = &v[3]; // 3番目の要素のアドレスを取得してポインタに代入
なお、vector の要素は、連続したアドレスに格納されていると保証されているので、それを前提としたコードを書いても問題ありません。
アルゴリズム
実は C++ には結構便利なアルゴリズムがいくつも用意されている。
参照:http://www.cplusplus.com/reference/algorithm/
ここでは、vector に対して特によく使うであろうアルゴリズムを少しだけ簡単に説明する
- count()
- find(itr, itr, val) : itr
- accumulate()
- sort()
- reverse()
count()
「count(オブジェクト名.begin(), オブジェクト名.end(), 値)」は、動的配列の最初から最後までを走査し、指定値の数を返します。
std::vector<int> v{3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5};
std::cout << std::count(v.begin(), v.end(), 5) << "\n"; // 要素5の数を返す
特定の範囲の要素の数を求めたい場合は、「count(v.begin() + i, v.begin() + k, val)」の様にイテレータで範囲を指定する。
find()
「find(オブジェクト名.begin(), オブジェクト名.end(), 値)」は、動的配列の最初から最後までを走査し、最初の要素へのイテレータを返します。
指定要素が無い場合は、オブジェクト名.end() を返します。
std::vector<int> v{3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5};
auto itr = std::find(v.begin(), v.end(), 5); // 最初の要素5へのイテレータを返す
if( itr != v.end() ) { // 発見した場合
発見した場合の処理
}
途中から検索したい場合は、第1引数に検索範囲先頭を指定します。
例えば、全ての要素位置を表示したい場合は、以下のように記述します。
std::vector<int> v{3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5};
auto itr = v.begin();
for (;;) {
itr = std::find(itr, v.end(), 5); // 要素5を検索
if( itr == v.end() ) // 発見できなかった場合
break;
std::cout << itr - v.begin() << "\n"; // インデックスを表示
++itr; // 次の位置から検索
}
find() の処理速度は O(N) です。
データ量が多く、かつ何度も検索を行う場合は、後に出てくる sort() を使って要素をあらかじめソートしておき、
binary_search(), lower_bound(), upper_bound() を使って二分探索をした方がトータルパフォーマンスが向上します。
詳しくはリンク先を参照してください。
accumulate()
「accumulate(オブジェクト名.begin(), オブジェクト名.end(), init)」は、動的配列の最初から最後まで、要素を積算(全加算)するものだ。
最後の引数は初期値で、通常は0を指定する。
なお、accumulate を利用するには「#include <numeric>」が必要。
#include <numeric>
.....
std::vector<int> v{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
std::cout << std::accumulate(v.begin(), v.end(), 0) << "\n";
一部を積算したい場合は、「accumulate(v.begin() + i, v.begin() + k, 0)」の様にイテレータで範囲を指定する。
「accumulate(&v[i], &v[k], 0)」のように、要素へのポインタで指定することも可能。
sort()
「sort(オブジェクト名.begin(), オブジェクト名.end())」は、動的配列の要素を昇順にソートしてくれる関数だ。
なお、sort を利用するには「#include <algorithm>」が必要。
#include <algorithm>
.....
std::vector<int> v{3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5};
std::sort(v.begin(), v.end());
一部をソートしたい場合は、「sort(v.begin() + i, v.begin() + k)」の様にイテレータで範囲を指定する。
「sort(&v[i], &v[k])」のように、要素へのポインタで指定することも可能。
reverse()
「reverse(オブジェクト名.begin(), オブジェクト名.end())」は、動的配列の要素を逆順にする関数だ。
std::vector<int> v{3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5};
std::reverse(v.begin(), v.end()); // 順序反転
for(auto x : v ) std::cout << x << " ";
std::cout << "\n";
演習問題:
- int 型、要素数100個の動的配列を作成し、各要素を [0, 99] の範囲でランダムに設定し、accumulate() を使い、それらの合計を求め表示しなさい。
- int 型、要素数100個の動的配列を作成し、各要素を [0, 99] の範囲でランダムに設定し、sort() を使い、それを昇順にソートしなさい。
- int 型、要素数100個の動的配列を作成し、各要素を [0, 99] の範囲でランダムに設定し、sort(), reverse() を使い、それを降順に並べ替えなさい。
#include <numeric>
.....
std::vector<int> v(100);
for(int i = 0; i < (int)v.size(); ++i)
v[i] = rand() % 100;
std::cout << std::accumulate(v.begin(), v.end(), 0) << "\n";
#include <numeric>
.....
std::vector<int> v(100);
for(int i = 0; i < (int)v.size(); ++i)
v[i] = rand() % 100;
std::cout << std::accumulate(v.begin(), v.end(), 0) << "\n";
#include <algorithm>
.....
std::vector<int> v(100);
for(int i = 0; i < (int)v.size(); ++i)
v[i] = rand() % 100;
std::sort(v.begin(), v.end());
std::reverse(v.begin(), v.end());
参考
通常、std::vector はテンプレートライブラリになっており、ソースが公開されている。
ソースを探しだして、読んでみると勉強になるかもしれない。
ただし、かなりレベルが高いコードなので、ちゃんと理解するにはそれなりの能力と知識と経験が必要だ。
上級者でないと無理だ。ちょっと見て理解不能と思ったら、すぐに勇気ある撤退をしよう。
型固定の動的配列 Vector を実装する演習問題も用意している。
これをやり遂げれば、vector の中身がどうなっているか、ある程度想像がつくようになるので、ぜひ挑戦してみて欲しい。