目次
- 文字列クラス std::string とは
- データ構造
- 準備:インクルード
- 宣言・初期化
- i 番目文字の参照(char に変換)、代入
- 文字列の連結
- 文字・文字列の追加
- 文字・文字列の削除
- その他のメンバ関数
- 文字列検索・置換
- std::to_string() :数値を std::string 文字列に変換
- 文字列配列
- 文字列比較
- 文字列分割 split
- 参考
- リファレンス
- コンストラクタ
- assign() : char&
- back() : char&
- begin() : string::iterator
- c_str() : char*
- capacity() : size_t
- clear() : void
- data() : char*
- empty() : bool
- end() : iterator
- erase(iterator) : iterator
- find(検索文字列) : size_t
- insert(iterator, char) : iterator
- pop_back() : void
- push_back(char) : void
- reserve(size_t) : void
- resize(size_t, char) : void
- shrink_to_fit() : void
- size() : size_t
- substr(位置, サイズ) : string
- swap(string&) : void
C++ 文字列クラス std::string とは
std::string とは C++ で標準に使用できる便利な文字列クラスでござるぞ。
C/C++ ではダブルクォートで文字列リテラルを表し、通常配列に文字を格納し加工することもできる。
strlen() など文字列の状態を返したり、sprintf() などの文字列を作成する関数などが用意されている。
しかし、リテラル文字列は動的な操作に不向きで、柔軟性に欠ける。
そのため、C++では動的にサイズを変更可能な文字列クラス std::string が導入された。
通常文字列と同じように [] 演算子で文字を参照・代入することはもちろん、サイズ情報等の取得や文字の挿入削除なども可能だ。
std::string は std::vector とよく似ている。size(), push_back() など、用意されているメンバ関数もほぼ同じで、
文字列特有のメンバ関数がいくつか用意されている。
vector との大きな違いは、文字列の最後にヌル文字('\0')が格納されている点だ。
※ 本稿では、初級者には難しいと思うので、どうしても必要な場合以外では「イテレータ」については言及しない。 イテレータを使用しなくても string は充分有用なクラスだと考えている。
データ構造
std::string のデータ構造の例を下図に示す。
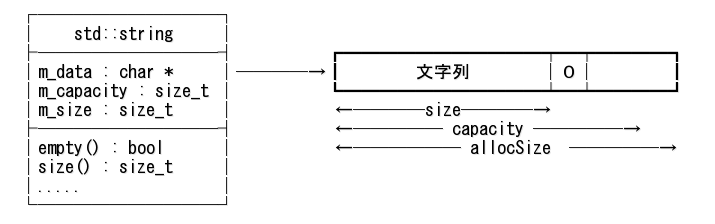
これはデータ構造の一例であり、あなたの環境の実際のデータ構造とは違うかもしれない。
サイズ、キャパシティの値を保持せず、データエリア末尾へのポインタを持つ実装もある。
重要なことは、データ領域が連続していることと、末尾に予備の領域を持つ、ということである。
ほとんど vector と同じなのだが、大きな違いはデータ末尾に終端文字 \0 が格納されているということである。
※ 某氏からコメントを頂いた: 末尾に \0 が無い実装も仕様上はありだそうである。 ただし c_str() は \0 付きの文字列へのポインタを返すので、c_str() が呼ばれた時に \0 を付加するというのも有りと言えば有りだそうだ。
vector のようなデータ構造は、途中の要素を挿入・削除した場合、要素の移動が必要なので、処理時間が O(N) となり、
要素数が極端に多いと処理に時間を要してしまうという問題がある。
従って、文字数が1万とかを超えると、パフォーマンスが低下する恐れがあるので注意。
準備:インクルード
string は C++標準のライブラリであり、「#include <string>」を記述することで利用可能になる。
名前空間は「std」なので、使用の度に「std::」を前置するか、または「using namespace std;」を記述しておく。
#include <string> // ヘッダファイルインクルード
int main()
{
std::string str; // ローカル変数として、str を生成
.....
}
#include <string> // ヘッダファイルインクルード
using namespace std; // 名前空間指定
int main()
{
string str; // ローカル変数として、str を生成
.....
}
宣言・初期化
本章では、string オブジェクトの宣言・初期化方法について説明する。
string オブジェクトを宣言するには、空stringを宣言する、サイズを指定して宣言する、サイズと全てのデータを指定して宣言する、 元データを指定して宣言する、他のオブジェクトを元にして宣言する、などの様にいくつもの方法がある。 本章ではそれらの方法を順次解説する。
ローカル変数またはグローバル変数として string オブジェクトを宣言すると、オブジェクトが生成され利用可能になる。 これらはスコープを外れると自動的に破棄される。
通常のクラスなので new で生成し、delete で破棄することも可能だ。
空文字列の生成
std::string オブジェクトを生成するには「std::string 文字列名;」 と記述する。
文字列名とは、宣言する文字列の名前のことだ。変数名と言ってもよい。
string はクラスなので、それを実体化したものはオブジェクトまたはインスタンスと呼ばれる。
下記は、string 型のオブジェクト str を宣言している例だ。
std::string str; // string 型のオブジェクト str の宣言
上記のコードのように、コンストラクタ引数が何も無い場合、空文字列が生成される。空文字列とは文字をひとつも持たない文字列のことである。
文字列の初期化
空文字列だけでなく、文字数・文字を指定して文字列を生成することも可能だ。
「std::string 文字列名(文字数, '文字');」と記述すると、指定された文字数のメモリを確保し、中身を指定された文字で初期化する。
std::string str(10, 'a'); // 文字数10、全ての要素を 'a' で初期化(すなわち "aaaaaaaaaa")
上記の方法では、文字が全て同じ文字列でないと初期化できない。
コンストラクタ引数に文字列リテラルを指定すると、その文字列で初期化することが出来る。
std::string str("abc"); // "abc" で初期化
もちろんポインタを使用してもよい。
char *data = "hoge";
std::string str(data); // "hoge" で初期化
「std::string 文字列名(char* first, char* last);」と記述すると、first から last が指す先までの文字列で初期化する。
厳密に言うと、last は最後の文字の次を指す。[first, last) の範囲を元に、文字列を初期化する。
通常文字列でデータを指定し、それを元に文字列を構築出来る。
char org_str[] = {'4', '6', '5'}; // 元データ
std::string str(org_str, std::end(org_str)); // 元データから文字列を生成
文字列リテラルの一部から文字列を作ることもできるぞ。
char *org_str = "abc123xyz"; // 元文字列
std::string str(org_str + 3, org_str + 6); // 元文字列の一部から文字列(この場合は"123")を生成
コピーコンストラクタ
コピーコンストラクタとは、同じ型のオブジェクトを渡され、それと同じ内容のオブジェクトを生成するコンストラクタのことである。
「std::string 文字列名(コピー元文字列名);」と記述する。
std::string org("123");
std::string x(org); // コピーコンストラクタ
上記のコードは org をコピーするので "123" という文字列をもつ x を生成する。
演習問題:
- 空文字列 str0 を宣言し、それを表示しなさい。
- "xyzzz" を値として持つ文字列 str を宣言し、それを表示しなさい。
- 'a' が 100個から成る文字列 a100 を宣言し("aaa....a" と a を100個書くのはNG)、表示しなさい。
- 文字リテラル "3.14159" の小数点以下3桁のみからなる文字列(この場合は "141")を生成し、表示しなさい。
- コピーコンストラクタのサンプルコードをビルドし、デバッガで正しくコピーされていることを確認しなさい。
- 文字と文字数を指定するコンストラクタの引数の順番が string(文字, 文字数) ではなく string(文字数, 文字) なのは何故なのかを考えなさい。
std::string str0;
std::cout << "'" << str0 << "'\n";
std::string str("xyzzz");
std::cout << "'" << str << "'\n";
std::string a100(100, 'a');
std::cout << "'" << a100 << "'\n";
char *ptr = "3.14159";
std::string str(ptr + 2, ptr + 5);
std::cout << "'" << str << "'\n";
vector のコンストラクタ引数が、要素数、値の順番で、値を省略できるので、それに合わせたのだと思われる。
まとめ:
- string 文字列名; で空文字列オブジェクトを生成
- string 文字列名(文字数, 文字); で文字*文字数の文字列オブジェクトを生成
- string 文字列名("文字列"); で指定された文字列のオブジェクトを生成
- string 文字列名(元文字列); で元文字列をコピーしてオブジェクトを生成
i 番目文字の参照(char に変換)、代入
[] 演算子(operator[](int)) を使って、通常の文字列と同じように、i 番目の文字の参照(char に変換)・代入が可能。
operator[](int) と聞くと身構える人がいるかもしれないが、「str[10]」の様に、普通の文字列の要素にアクセスする時と同じ記述だ。
恐れることは何も無い。
下記は、i 番目の文字の参照(char に変換)と代入例。普通の参照(char に変換)・代入とまったく同じでしょ。
std::string str("31415926535");
for (int i = 0; i < 10; ++i)
std::cout << str[i] << " "; // str の i 番目の要素を表示
const int SZ = 10; // 文字数
std::string str(SZ, 'a'); // 10 文字の 'a' から成る str を生成
for(int i = 0; i < SZ; ++i)
str[i] = 'b' + i; // 文字を 'b', 'c' ... に設定
std::cout << str << "\n";
演習問題:
- string str(100, ' '); を宣言し、各文字を 'a' ~ 'z' のランダムなものに置き換えるコードを書きなさい。
const int SZ = 100;
std::string str(SZ, ' ');
for(int i = 0; i < SZ; ++i)
str[i] = rand() % 26 + 'a';
std::cout << str << "\n";
文字列の連結
- operator+(str1, str2)
+演算子(operator+())により、文字列を連結することができる。
std::string str1("12");
std::string str2("xyz");
std::string str3 = str1 + str2; // + 演算子により str1 と str2 を連結
std::cout << str3 << "\n";
上記は、str1 と str2 を連結する例だ。
演習問題:
- 上記コードをビルド・実行してみなさい。
- 文字列を適当に変えてビルド・実行してみなさい。
- str1 + str2 を str2 + str1 に変えるとどうなるか予想し、ビルド・実行してみなさい。
- コンソールから文字列を2つ入力し、それらを連結して表示するプログラムを書きなさい。
文字・文字列の追加
- push_back(文字) : void
- operator+=(文字) : string
- operator+=(文字列) : string
- insert(イテレータ, 文字) : イテレータ
push_back(文字) : void
文字を末尾に追加するには push_back(文字); または += 演算子を使う。
std::string str; // 空の文字列を生成
str.push_back('Z'); // 末尾に 'Z' を追加
str += '0'; // 末尾に '0' を追加
std::cout << str << "\n";
operator+=(文字) : string、operator+=(文字列) : string
push_back() は文字しか追加できないが、+= 演算子は文字列を追加することも出来るし、 コードが見やすいので、通常は += 演算子の方が使用される。
先頭に文字を挿入したい場合は、前節に出てきた + 演算子を使用する。
std::string str("xyz");
str = "12" + str; // str の先頭に "12" を挿入と同じ
std::cout << str << "\n";
push_back(), += 演算子共に、処理時間は O(1) で高速。O(式) は処理時間を表す数学的な記法。「ビッグ・オー記法」と呼ばれる。 O(1) は文字数に依らず常に一定時間で処理出来るという意味で、高速なのだ。
insert(イテレータ, 文字) : イテレータ
任意の位置に文字を挿入したい場合は insert(iterator, 文字) を使う。
insert(iterator, 文字) は、第1引数に挿入する場所へのイテレータを、第2引数に挿入する文字を指定する。
イテレータとは抽象化されたポインタのこと。ちゃんとした説明は長くなるし、初級者には理解が大変なのでここでは省略する。
i 番目に挿入したい場合は「文字列名.begin() + i」と書くと覚えて欲しい。
std::string str("1234"); // "1234" という文字列
str.insert(str.begin() + 2, '-'); // [2] の位置に '-' を挿入
std::cout << str << "\n"; // 結果は "12-34" となる
insert() の処理時間は O(N) 。O(N) とは文字素数に比例して処理時間を要するという意味。
文字数が100倍になると、処理時間も100倍になる。
文字列をずらす処理を行う必要があるので、その分処理時間を食うというわけだ。
それに対して push_back(), operator+=() は O(1) なので、文字数がいくら増えても常に一定時間で処理が終わる。
ただし、文字数が少ない(数10文字程度)場合であれば、string は十分高速なので、処理時間は問題にはならない。
演習問題:
- 空の string を生成し、末尾に文字 'a', 'b' ~ 'j' を1文字ずつ追加するコードを書きなさい。
- "1234567890" の string を生成し、[5] の位置に '*' を挿入するコードを書きなさい。
std::string str;
for(int i = 0; i < 10; ++i)
str += 'a' + i;
std::cout << str << "\n";
std::string str;
for(char ch = 'a'; ch <= 'j'; ++ch)
str += ch;
std::cout << str << "\n";
std::string str("1234567890"); // "1234" という文字列
str.insert(str.begin() + 5, '*'); // [5] の位置に '*' を挿入
std::cout << str << "\n";
まとめ:
- 文字列名.push_back(文字); で末尾に文字を追加
- 文字列名 += 文字; で末尾に文字を追加
- 文字列名 += 文字; で末尾に文字を追加
- 文字列名 += 文字列; で末尾に文字列を追加
- 文字列名.insert(イテレータ, 文字); で任意の位置に文字を挿入
文字・文字列の削除
- pop_back() : void
- erase(イテレータ) : イテレータ
- erase(first, last) : イテレータ
pop_back() : void
最後の文字を削除したい場合は pop_back() を用いる。
std::string str("12345");
str.pop_back(); // 末尾文字(この場合は '5')を削除
std::cout << str << "\n";
pop_back() も push_back() 同様、処理時間は O(1) と高速である。
空の string に対して、pop_back() を実行するとデバッグモード・リリースモード共に例外が発生する(VS2010、VS2013)。
次の章で説明する empty() または size() で string が空でないことを事前に確認するようにした方がよい。
pop_back() は何故か void 型で、削除した文字を返さない。 なので、最後の文字を取り出して削除したい場合は、後で説明する back() を使用する。
erase(イテレータ) : イテレータ
任意の位置の文字を削除したい場合は erase(iterator) を使用する。
std::string str("01234");
str.erase(str.begin() + 2); // 3番目の要素('2')を削除
std::cout << str << "\n";
erase() で途中の文字を削除すると、サイズが一つ減り、削除された位置以降の文字がひとつずつ前に移動される。
イテレータは前節で言及したように、削除する文字位置を示すもので、先頭からi 番目の文字は「文字列名.begin() + i」で指定する。
erase(first, last) : イテレータ
erase(first, last) で範囲 [first, last) の文字を一度に削除することが出来る。first, last はイテレータだ。先頭からi 番目の文字は「文字列名.begin() + i」で指定する。
std::string str("01234");
str.erase(str.begin() + 2, str.begin() + 4); // '2', '3' を削除
std::cout << str << "\n";
演習問題:
- pop_back() で末尾を削除・表示するコードを書き、ビルド・実行し、末尾データが削除されたことを確認しなさい。
- erase() で途中の文字を削除・表示し、本当に削除されたことを確認しなさい。
std::string str("1234x");
str.pop_back();
std::cout << str << "\n";
std::string str("012345");
str.erase(str.begin() + 3); // [3] の文字:'3' が消えるはず
std::cout << str << "\n";
まとめ:
- 文字列名.pop_back(); で最後の文字を削除
- 文字列名.erase(イテレータ); で任意の位置の文字を削除
その他のメンバ関数
ここまで、文字列オブジェクトの宣言、文字の参照・代入・追加・削除方法について説明した。
それらにより文字列クラスを使うことができるはずだ。
実は文字列クラスには上記以外にも便利な機能がメンバ関数としていくつも用意されている。
文字列が空かどうかをチェックしたり、文字数を調べたり、文字列置換することもできる。
これらは通常文字列に対する明らかなアドバンテージである。
文字列の状態を取得
- empty() : bool
- size() : size_t
- length() : size_t
- capacity() : size_t
「bool empty()」は文字列が空かどうかを判定する関数。
次に出てくる size() を使って、size() == 0 と判定するのと同等だ。
が、コンテナクラスによっては size() 計算よりも empty() の方が高速な場合がある。
なので、string などのコンテナクラスに対しては empty() を使うことが推奨されている。
std::string str;
if( str.empty() )
std::cout << "empty.\n";
else
std::cout << "not empty.\n";
str = "abc";
if( str.empty() )
std::cout << "empty.\n";
else
std::cout << "not empty.\n";
「size_t size()」、「size_t length()」は、文字数を返す関数。これらは同じものである。
通常文字列の文字数は「length()」だが、vector などとの互換性のために「size()」があるのだと推測される。
※ size_t はサイズを表す型で、符号なし整数の組み込み型である。ちなみに、sizeof() も size_t 型を返す。
std::string str;
std::cout << str.size() << "\n"; // 0 が表示される
std::cout << str.length() << "\n"; // 0 が表示される
str = "abc";
std::cout << str.size() << "\n"; // 3 が表示される
std::cout << str.length() << "\n"; // 3 が表示される
「size_t capacity()」は、文字列が確保しているメモリに入る文字数、すなわち現在のデータ領域容量を返す関数。
string は実際の文字数より若干大目にメモリを確保している。これは文字が増えた時、常にメモリを再確保するのではなく、
余裕を持たせておくことで、頻繁なメモリ確保とデータのコピーを避けるためだ
(参照:文字列クラス 演習問題の図)。
std::string str;
std::cout << str.capacity() << "\n"; // VSC2013 では 15 が表示された
文字列の一部を取得
- front() : charへの参照
- back() : charへの参照
- substr(位置、サイズ) : string
- c_str() : char へのポインタ
- data() : char へのポインタ
「front()」は先頭文字を返す関数。「文字列名[0]」と記述するのと同等。
「back()」は末尾文字を返す関数。「文字列名[文字列名.size() - 1]」と記述するのと同等。
front() はあまりありがたみが無いが、back() はタイプ数が大幅に減るし、分かりやすいので存在価値が高いぞ。
std::string str("abcxyz");
std::cout << str.front() << " " << str.back() << "\n"; // 'a', 'z' が表示される
「substr(位置、サイズ)」は、文字列を切り出すメンバ関数。
std::string str("012345");
std::string sub = str.substr(2, 3); // [2] の位置から3文字切り出す
std::cout << sub << "\n";
「c_str()」、「data()」は文字列データ先頭アドレスを返す関数。「&文字列名[0]」と記述するのと同等。
std::string は導入当初、数値との相互変換など機能が不足していた。
そこで、これらのメンバ関数を使って従来の C の文字列関数を呼ぶことで、その欠点を補ってきたというわけだ。
string は通常文字列と同じようにデータ領域が連続したアドレスだということが保証されている。
なので、文字列アドレスを他の関数に渡して処理することも可能だ。
std::string str("12345");
cout << strlen(str.c_str()) << "\n";
文字列の状態を変更
- clear() : void
- resize(サイズ) : void
- resize(サイズ, 文字) : void
- reserve(サイズ) : void
- swap(文字列) : void
- shrink_to_fit() : void
std::string str = "hogehoge";
str.clear(); // str を空にする
「clear()」は文字列を空にする関数。
サイズを0にするだけ。メモリが解放されるわけではない。
メモリを解放したい場合は後で説明する shrink_to_fit() または swap() イディオムを使用する。
「resize(size_t sz)」は文字数を指定サイズに設定する関数。
sz が現在のキャパシティを超えていれば、メモリがアロケートされ,文字列がコピーされる。
サイズが増えた部分の値を指定したい場合は、「resize(size_t sz, 文字)」と、第2引数で文字を指定する。
サイズが減っても、その分のメモリが解放されるわけではない。
不要になったメモリを解放したい場合は後で説明する shrink_to_fit() または swap() イディオムを使用する。
「reserve(size_t sz)」はキャパシティを指定する関数。
文字列を大量に追加する場合、メモリのアロケートと文字列コピーが多く呼ばれる場合がある。
そうなるとパフォーマンスが低下する場合があるので、追加する文字の数が予めわかっていれば、reserve() でメモリを確保する方がパフォーマンス的に好ましい。
std::string str;
const int N = 10000;
str.reserve(N); // 予め1万個分の領域を確保しておいた方が高速
for(int i = 0; i < N; ++i)
str.push_back(i);
「swap(文字列名)」は引数で指定されたオブジェクトと内容を入れ替える関数。
std::string v, z;
v, z に文字列を設定
v.swap(z); // v と z の内容を入れ替える
先に書いたように、clear() を行ってもメモリは解放されないので、C++11以前では以下のようなコードが使用されていた。
std::string str;
str に文字列を設定
std::string().swap(str); // 空のテンポラリ文字列を生成し、中身を入れ替える
「shrink_to_fit()」は、C++11 で追加された関数で、キャパシティを現在のサイズの値にし、余分なメモリを解放する関数。
C++11以前では、shrink_to_fit() がなかったので以下のようなイディオムが使用されていた。
std::string str;
str に文字列を設定
std::string(str).swap(str); // v をコピーしたテンポラリ文字列を生成し、中身を入れ替える
演習問題:
- std::string str; に対して、empty(), size(), capacity() をコールし、それぞれの値を表示するコードを書きなさい。
- std::string str("314"); に対して、empty(), size(), capacity() をコールし、それぞれの値を表示するコードを書きなさい。
- std::string str("314"); に対して、front(), back() をコールし、それぞれの値を表示するコードを書きなさい。
- std::string str("314"); に対して、c_str(), data() をコールし、返されたアドレスの内容を確認しなさい。
- atoi() をコールし、文字列の整数(例えば "123")を int 型の整数値に変換するコードを書きなさい。
- std::string str("314"); に対して、clear() をコールし、empty(), size(), capacity() の値を表示するコードを書きなさい。
- std::string str("314"); に対して、resize(8) をコールし、empty(), size(), capacity()、文字列を表示するコードを書きなさい。
- std::string str("314"); に対して、resize(8, 'a') をコールし、empty(), size(), capacity()、文字列を表示するコードを書きなさい。
- std::string str("314"); に対して、resize(1) をコールし、empty(), size(), capacity()、文字列を表示するコードを書きなさい。
- std::string str("314"); に対して、reserve(100) をコールし、empty(), size(), capacity()、文字列を表示するコードを書きなさい。
- std::string str("314"); に対して、reserve(1) をコールし、empty(), size(), capacity()、文字列を表示するコードを書きなさい。
- std::string str("314"); に対して、resize(1); shrink_to_fit() をコールし、empty(), size(), capacity()、文字列を表示するコードを書きなさい。
- std::string str("314"), z("xyzzz"); に対して、str.swap(z); を実行し、それぞれの内容を表示するコードを書きなさい。
std::string str;
cout << str.empty() << "\n";
cout << str.size() << "\n";
cout << str.capacity() << "\n";
std::string str("314");
cout << str.empty() << "\n";
cout << str.size() << "\n";
cout << str.capacity() << "\n";
std::string str("314");
cout << str.front() << "\n";
cout << str.back() << "\n";
std::string str("314");
int *data = str.data();
int *c_str = str.c_str();
std::string str("123");
cout << atoi(str.c_str()) << "\n";
std::string str("314");
str.clear();
cout << str.empty() << "\n";
cout << str.size() << "\n";
cout << str.capacity() << "\n";
cout << str << "\n";
std::string str("314");
str.resize(8);
cout << str.empty() << "\n";
cout << str.size() << "\n";
cout << str.capacity() << "\n";
cout << str << "\n";
std::string str("314");
str.resize(8, 'a');
cout << str.empty() << "\n";
cout << str.size() << "\n";
cout << str.capacity() << "\n";
cout << str << "\n";
std::string str("314");
str.resize(1);
cout << str.empty() << "\n";
cout << str.size() << "\n";
cout << str.capacity() << "\n";
cout << str << "\n";
std::string str("314");
str.reserve(100);
cout << str.empty() << "\n";
cout << str.size() << "\n";
cout << str.capacity() << "\n";
cout << str << "\n";
std::string str("314");
str.reserve(1);
cout << str.empty() << "\n";
cout << str.size() << "\n";
cout << str.capacity() << "\n";
cout << str << "\n";
std::string str("314");
str.resize(1);
cout << str << "\n";
cout << str.empty() << "\n";
cout << str.size() << "\n";
cout << str.capacity() << "\n";
str.shrink_to_fit();
cout << str.empty() << "\n";
cout << str.size() << "\n";
cout << str.capacity() << "\n";
std::string str("314");
std::string z("xyzzz");
str.swap(z);
std::cout << str << "\n";
std::cout << z << "\n";
文字列検索・置換
- find(検索文字列, 検索開始位置=0)
- rfind(検索文字列, 検索開始位置=文字列長)
- replace(位置, 置換文字数, 置換文字列)
「find(検索文字列, 開始位置=0)」は指定された検索文字列を、指定位置から末尾に向かって検索し、
マッチした場合はその位置を返す(型は size_t)。
開始位置を省略した場合は、先頭から検索する。
検索文字列が無かった場合は size_t の最大値を返す( -1 に相当する値)。
std::string str("abcabc");
std::cout << (int)str.find("b") << "\n"; // マッチする場合
std::cout << (int)str.find("b", 3) << "\n"; // 3文字目から末尾に向かって検索
std::cout << (int)str.find("x") << "\n"; // マッチしない場合
find には上記以外にもいくつかのコール方法がある。詳しくは ここ を参照。
「rfind(検索文字列, 検索開始位置=文字列長)」は指定された検索文字列を、指定位置から先頭に向かって検索し、
マッチした場合はその位置を返す(型は size_t)。
開始位置を省略した場合は、末尾から検索する。
検索文字列が無かった場合は size_t の最大値を返す( -1 に相当する値)。
std::string str("abcabc");
std::cout << (int)str.rfind("b") << "\n"; // マッチする場合
std::cout << (int)str.rfind("b", 3) << "\n"; // 3文字目から先頭に向かって検索
std::cout << (int)str.rfind("x") << "\n"; // マッチしない場合
rfind には上記以外にもいくつかのコール方法がある。詳しくは ここ を参照。
「replace(位置, 置換文字数, 置換文字列)」は指定位置から指定文字数を置換文字列で置き換える。
下記は、"12345" の 1文字目から2文字を "xyz" に置き換える例。
std::string str("12345");
str.replace(1, 2, "xyz");
std::cout << str << "\n";
演習問題:
- string を引数に取り、中身の "abc" 全てを "XYZZZ" に置換して返す関数
std::string replaceAbcToXyzzz(const std::string &str) を実装しなさい。
replaceAbcToXyzzz("abcabc") が "XYZZZXYZZZ" を、 replaceAbcToXyzzz("abcababc") が "XYZZZabXYZZZ" を、 replaceAbcToXyzzz("") が "" を返すことを確認しなさい。
std::string replaceAbcToXyzzz(const std::string &str)
{
std::string str2(str);
int ix = 0;
while( (ix = str2.find("abc", ix)) >= 0 ) {
str2.replace(ix, strlen("abc"), "XYZZZ");
}
return str2;
}
std::to_string() :数値を std::string 文字列に変換
C++11 以前では、数値を std::string に変換する鉄板な方法がなく、いろいろな方法があった。
例えば、以下は任意の型を std::string に変換するテンプレート関数だ。
#include <sstream> // std::ostringstream
template <typename T> std::string tostr(const T& t)
{
std::ostringstream os; os<<t; return os.str();
}
上記関数を使えば、整数やdouble等を文字列に変換することが出来る。
int main()
{
std::string s = tostr(123); // 整数を文字列に変換
std::string d = tostr(3.1415); // 浮動小数点数を文字列に変換
.....
}
上記でもたいていの場合は充分なのだが、テンプレート関数をいちいち記述(コピペ?)するのは面倒だ。
そこで、C++11 から、数値を std::string に変換する関数 std::to_string(数値) が導入された。
使い方は、先の tostr() と同じで、とっても簡単。
#include <iostream>
#include <string>
int main() {
std::string s = std::to_string(123); // 整数を文字列に変換
std::string d = std::to_string(3.1415); // 浮動小数点数を文字列に変換
.....
}
演習問題:
- 上記をビルド・デバッガで実行し、正しく変換されていることを確認しなさい。
文字列配列
string 文字列の配列を利用したい場合がある。そのような時は std::vector を使って以下ののように記述する。
std::vector<std::string> strList; // 文字列配列
配列への文字列の追加は strList.push_back("hoge") などを用いる。詳しくは std::vector を参照。
文字列配列をリテラルで初期化したい場合は、下記の様に初期化子を使用する。ただし、これはC++11以上で有効なので注意。
std::vector<std::string> strList =
{
"abc", "123", "xyzzz"
};
このように宣言しておくと、strList[1] などと、普通の配列と同じ様に参照することが出来る。
std::vector は途中への挿入削除は高速ではないので、要素数が多く途中の挿入削除が頻繁に起こる場合は、あまりよろしくない。
そのような場合は、下記の様に std::list を使用することをお勧めする。
※ 配列要素数が100未満と少なければ、挿入削除を行っても std::vector は充分高速で扱い易い。
std::list<std::string> strList =
{
"abc", "123", "xyzzz"
};
ただし、list にしてしまうと str[ix] の様には参照できず、イテレータを使わないといけない。詳しくは list を参照されたし。
演習問題:
- 複数の要素を持つ std::vector<std::string> のオブジェクトを作成し、[] 演算子で中身が取り出せることを確認しなさい。
- 複数の要素を持つ std::list<std::string> のオブジェクトを作成し、[] 演算子で中身が取り出せないことを確認しなさい。
- 複数の要素を持つ std::list<std::string> のオブジェクトを作成し、イテレータで回して全ての中身を表示するコードを書きなさい。
文字列比較
引数に文字列を2つとる比較演算子(== != < <= > >=)が定義されているので、「if (str == "abc") { ..... }」と普通の型と同じように比較することが出来る。
比較は大文字小文字を区別する厳密比較である。
以下は、文字列配列の中から、一致するものを探す例だ。
std::vector<std::string> strList =
{
"abc", "123", "zzz", "xyzzz"
};
int ix = 0;
for(; ix < (int)stList.size(); ++ix) {
if( strList[ix] == "zzz" ) break; // "zzz" を検索
}
if( ix < (int)stList.size() ) {
// "zzz" を発見した場合の処理
} else {
// "zzz" を発見出来なかった場合の処理
}
演習問題:
- 上記コードをビルドし、デバッガ等で正しく動作することを確認しなさい。
文字列分割 split
split とは、文字列を指定された区切り文字で分割する処理のことだ。
例えば、"abc/xyz" を '/' で split すると {"abc", "xyz"} となる。2つだけでなく、区切り文字の個数だけ分割することができる。
std::string には何故か使用頻度の高いメソッドが無い場合が多い。指定文字で文字列を分割する split() もその一つだ。
なので、split は何らかのライブラリを使用するか、自分で定義しなくてはいけない。
以下は std::getline() を用いて、split() を定義する例だ。getline() は通常改行でテキストを分割するが、実は第3引数で分割文字を指定することが出来る。
#include <vector>
#include <string>
#include <sstream> // std::ostringstream
std::vector<std::string> split(const std::string &str, char sep)
{
std::vector<std::string> v;
std::stringstream ss(str);
std::string buffer;
while( std::getline(ss, buffer, sep) ) {
v.push_back(buffer);
}
return v;
}
std::getline() を使用せず、自分で1から書くと、以下のようになる。
std::vector<std::string> split(const std::string &str, char sep)
{
std::vector<std::string> v; // 分割結果を格納するベクター
auto first = str.begin(); // テキストの最初を指すイテレータ
while( first != str.end() ) { // テキストが残っている間ループ
auto last = first; // 分割文字列末尾へのイテレータ
while( last != str.end() && *last != sep ) // 末尾 or セパレータ文字まで進める
++last;
v.push_back(std::string(first, last)); // 分割文字を出力
if( last != str.end() )
++last;
first = last; // 次の処理のためにイテレータを設定
}
return v;
}
演習問題:
- 上記関数を使用して、split("abc:xyz:12345", ':') が正しい結果を返すことを確認しなさい。
- サンプルソースを見ずに、自分で split() を実装してみなさい。
参考
通常、std::string はテンプレートライブラリになっており、ソースが公開されている。
ソースを探しだして、読んでみると勉強になるかもしれない。
ただし、かなりレベルが高いコードなので、ちゃんと理解するにはそれなりの能力と知識と経験が必要だ。
上級者でないと無理だ。ちょっと見て理解不能と思ったら、すぐに勇気ある撤退をしよう。
文字列クラス String を実装する演習問題も用意している。
これをやり遂げれば、string の中身がどうなっているか、ある程度想像がつくようになるので、ぜひ挑戦してみて欲しい。