
目次
双方向リストクラス std::list とは
std::list とは C++ で標準に使用できる便利な双方向リストクラスでござるぞ。
「双方向リスト」とは、要素を格納するノードが前後のノードへのポインタを持ち、どの位置への挿入・削除でも O(1) と高速に処理できるコンテナクラスだぞ。
※ 「コンテナクラス」とは、単一タイプ・データ構造の複数のデータを取り扱うためのクラスのことだぞ
std::list と対比されるのは std::vector である。
vector は末尾への挿入・削除は O(1) と高速だが、それ以外の位置への挿入・削除は O(N) で、データ数に比例した処理時間を要してしまう。
その半面、どの位置のデータへも O(1) と高速にアクセス(参照・代入)することができる。
任意の位置へのアクセスをランダム・アクセスと呼ぶので、vector はランダム・アクセスが O(1) ということ。
これに対して、std::list は、末尾に限らず、どの位置での挿入削除も O(1) と高速に処理することができる。 が、N 番目のデータ位置に移動するには先頭、または末尾、または現在位置からポインタをたどる必要があり、 ランダム・アクセスの処理速度が O(N) である。
つまり、std::list と std::vector はランダム・アクセスと任意の位置への挿入・削除処理時間が相補的ということである。
| ランダム・アクセス | 任意位置への挿入・削除 | |
| std::vector | O(1) | O(N) |
| std::list | O(N) | O(1) |
vector, list のどちらかが一方的に優れているというわけではなく、上記のような特性があるので、用途により使い分けて欲しい。
ただ、vector のページ でも書いたが、データ数が少ない場合(通常、数10個程度)は vector の挿入削除も充分高速で、
扱い易いので、通常は vector を使用することをお薦めする。
ちなみに、初期のテキストエディタでは、内部データ構造として、文字列を双方向リストで管理することが多かった(ただし Emacs は除く)。
コードで書けば std::list<std::string> となる。テキストエディタで行をランダム・アクセスすることは稀なので、これで通常は問題が無かったわけだ。
データ構造
std::list のデータ構造の例を下図に示す。
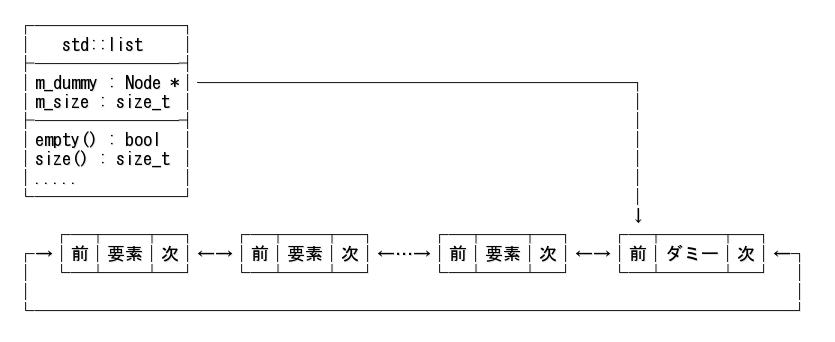
vector との大きな違いは、各要素が独立したメモリ領域(これをノードと呼ぶ)に入っているという点である。 そしてそれらのノードはポインタにより相互にリンクされている。
これはデータ構造の一例であり、あなたの環境の実際のデータ構造とは違うかもしれない。
上図ではリストが空であった場合でも処理を同一にできるようダミーノードがある(これを環状リンクと呼ぶ)が、
ダミーノードが無い実装もある。
重要なことは、各要素がノードに入っていて、前後のノードへのポインタを保持している、ということである。 std::list が、「双方向(リンク)」と呼ばれるのはそのためだ。
準備:インクルード
まずは、list を使うための準備について説明する。
list は C++標準ライブラリに含まれており、「#include <list>」を記述することで利用可能になる。
名前空間は「std」なので、使用の度に「std::」を前置するか、または「using namespace std;」を記述しておく。
#include <list> // ヘッダファイルインクルード
int main()
{
std::list<int> lst; // ローカル変数として、lst を生成
.....
}
#include <list> // ヘッダファイルインクルード
using namespace std; // 名前空間指定
int main()
{
list<int> lst; // ローカル変数として、lst を生成
.....
}
宣言・初期化
本章では、list オブジェクトの宣言方法について説明する。
list オブジェクトを宣言するには、空listを宣言する、サイズを指定して宣言する、サイズと全てのデータを指定して宣言する、 元データを指定して宣言する、他のオブジェクトを元にして宣言する、のようにいくつもの方法がある。 本章ではそれらの方法を順次解説する。
ローカル変数またはグローバル変数として list オブジェクトを宣言すると、オブジェクトが生成され利用可能になる。
これらはスコープを外れると自動的に破棄される。
通常のクラスなので new で生成し、delete で破棄することも可能だ。
単純な宣言
std::list オブジェクトを生成するには「std::list<型> オブジェクト名;」 と記述する。
オブジェクト名とは、宣言する双方向リストを識別するための名前のことだ。変数名と言ってもよい。
list はクラスなので、それを実体化したものはオブジェクトまたはインスタンスと呼ばれる。
下記は、int 型の双方向リストdata を宣言している例だ。
std::list<int> lst; // int 型の双方向リスト lst の宣言
当然、型の部分はどんな型でも構わない。char や double や、自分で定義した構造体、クラスでもOKだ。
※ ただし、初期化時にデフォルトコンストラクタ、バッファ拡張時にコピーコンストラクタが呼ばれことがあるので、
それらがちゃんと定義されている必要がある。
また、vector などのコンテナクラスや string などを指定することも出来る。
「std::list<型> オブジェクト名;」には要素数の指定が無いじゃないかと気づいた人は観察力がある。要素数の指定方法は次節で説明する。
このようにして宣言したオブジェクトの要素数は0だ。データを追加するには次の章で説明する push_back() などを使う。
< > は何だ?と思う人もいるかもしれない。これはC++のテンプレートという機能を使うための記法だ。
テンプレートを完全に理解するのは難易度が高いので、深く理解しようとすると先に進めなくなる。
深入りはせず、現在のところは取り扱うデータの型をこういう書き方で指定すると無条件で覚えてほしい。
要素数を指定した宣言
list は後でサイズを増減させることが出来るが、あらかじめ要素数を指定してオブジェクトを作ることも出来る。
vector の場合、データ領域が連続しているために、データ領域が足りなくなった場合にメモリのアロケートとデータコピーが必要だ。
だが、list は個々のデータ領域が独立なので、予め要素数を指定してオブジェクトを作るメリットは vector ほどは無い。
構文は「std::list<型> オブジェクト名(要素数);」だ。
std::list<int> lst(123); // int 型で、初期要素数 123 の双方向リスト lst の宣言
配列では要素数を「[要素数]」で指定するが、list では「(要素数)」で指定する。実はこれ、コンストラクタの引数なのである。
要素の初期化
要素数を指定するだけでなく、全要素の値を指定することも可能だ。
「std::list<型> オブジェクト名(要素数, 値);」と記述すると、指定された数の要素を確保し、全ての要素を指定された値で初期化する。
std::list<int> lst(10, 5); // 要素数10、全ての要素の値5 で初期化
上記の方法では、値が全て同じ場合でないと初期化できない。
「std::list<型> オブジェクト名(型* first, 型* last);」と記述すると、first から last が指す先までのデータで双方向リストを初期化する。
厳密に言うと、last は最後の元データの次を指す。[first, last) の範囲を元に、双方向リストを初期化する。
通常配列でデータを指定し、それを元に双方向リストを構築出来る。
int org_data[] = {4, 6, 5}; // 元データ
std::list<int> lst(org_data, org_data + 3); // 元データから双方向リストを生成
配列末尾へのポインタは org_data + 3 と記述しているが、データ配列サイズが変わった時に、修正しなくてはならないので、危険だ。
C++0x(VS2010以上)で std::end(配列名) という関数が追加され、配列末尾へのポインタを返してくれるようになった。
これを使えば、上記は下記のように記述することが出来る。
int org_data[] = {4, 6, 5}; // 元データ
std::list<int> lst(org_data, std::end(org_data)); // 元データから双方向リストを生成
実は上記の記述方法は古い書き方で、C++11(VS2013以上)から初期化子で初期値を直接指定可能になった。
「std::list<型> オブジェクト名{値0, 値1, 値2, ... 値N-1};」と記述できる。
std::list<int> lst{4, 6, 5}; // データ列を指定して双方向リストを生成
こちらの方法の方が直感的で分かりやすく、行数も短い。C++11 が利用可能であれば、この記法を使うことを強く薦める。
※ ちなみに、「std::list<型> オブジェクト名 = {値0, 値1, 値2, ... 値N-1};」と書いてもよい。
コピーコンストラクタ
コピーコンストラクタとは、同じ型のオブジェクトを渡され、それと同じ内容のオブジェクトを生成するコンストラクタのことである。
「std::list<型> オブジェクト名(コピー元オブジェクト名);」と記述する。
当然ながら、コピー元オブジェクトと生成するオブジェクトは通常同じ型である。
※ 暗黙の型変換が可能な型であれば、コピー元オブジェクトとして指定可能ではある。
std::list<int> org{1, 2, 3};
std::list<int> x(org); // コピーコンストラクタ
上記のコードは org をコピーするので {1, 2, 3} という値をもつ双方向リスト x を生成する。
※ 余談:list オブジェクトの宣言方法は vector のそれと全く同一である。このように仕様に共通性があることを直交性があると言う。
直交性がある仕様は、ひとつ覚えると他にもすぐ使えて便利である。
だたし、後で出てくるが、ランダム・アクセスなど、list と vector の仕様は完全に同一ではないので、例外的な部分はしっかり抑えておく必要はある。
演習問題:
- char 型の双方向リスト str を宣言しなさい。
- 要素数3の double 型の双方向リスト pos を宣言しなさい。
- char 型、値 'a'、要素数10の双方向リスト a を宣言するコードをビルドし、デバッガで中身を確認しなさい。
- double 型、1.1, 2.2, 3.3, 4.4 の4つの値をもつ双方向リスト d を宣言するコードをビルドし、デバッガで中身を確認しなさい。
- コピーコンストラクタのサンプルコードをビルドし、デバッガで正しくコピーされていることを確認しなさい。
std::list<char> str;
std::list<double> pos(3);
std::list<char> a(10, 'a');
std::list<double> d{1.1, 2.2, 3.3, 4.4};
std::list<int> org{1, 2, 3};
std::list<int> x(org); // コピーコンストラクタ
値の参照、代入
イテレータ
落胆する人もいるかもしれないが、list には operator[](size_t) が無い。つまり lst の ix 番目の要素を lst[ix] で参照することが出来ない。
何故できないかと言うと、最初の方で書いたように、ix 番目のデータに移動するコストが O(N) と高いので、
コーダが安易にランダム・アクセスを行うコードを書いてパフォーマンスを低下させないよう、あえて operator[](size_t) が定義されていないのだ。
※ 余談:
ちなみに、筆者がテキストエディタ ViVi の開発を始めた時、テキストを行ごとに双方向リストで管理していた。
フレームワークは MFC(Microsoft Foundation Class ライブラリ) を使っていたのだが、MFC には双方向リストクラス CList があり、それには GetAt(int), SetAt(int, const T&) というメソッドがあり、
なんとランダム・アクセスが可能になっていた。で、筆者は「おおっ、これは便利だ」と思い、安易にそれらのメソッドを使っていたのだが、
行数が増えると編集処理がかなり遅くなるという問題が発生した。
後で高速化が必要になり苦労した(今となってはいい)思い出がある。本稿の読者にはこのような轍を踏まないようにしてほしい。
※ 余談終わり
では、どうやって任意の箇所のデータを参照するかと言うと、イテレータ(iterator)というものを利用する。
イテレータとは抽象化されたポインタのことである。ポインタなので、要素を指していてイテレータ経由で要素の参照・修正が出来、別の要素に移動することが出来る。

もう少し具体的に言うと、begin() で先頭, end() で末尾の次の要素へのイテレータを取得でき、++ または -- 演算子でイテレータを進める、戻すことができ、
* 演算子でイテレータが指す要素を参照することができる。
++, -- でひとつ移動でき、* で要素を参照できるという機能は通常のポインタと同じである。
が、内部的にはポインタと同じというわけではない。これが抽象化されたポインタと呼ばれる理由だ。
イテレータの型は std::list<型>::iterator と記述する。少々めんどくさい。
たとえば、std::list<int> lst の最初の要素を指すイテレータを取得したい場合は以下のように記述する。
std::list<int> lst;
std::list<int>::iterator itr = lst.begin(); // 最初の要素を指すイテレータ
イテレータ型の記述は少々長ったらしく面倒だが、C++0x(VS2010以上)からは auto で型推論が可能になったので、 上記は以下のように記述するのが普通である。
std::list<int> lst;
auto itr = lst.begin(); // 最初の要素を指すイテレータ
イテレータが指すデータを参照する場合は、ポインタと同じ用に * 演算子を使用する。右辺値として記述すれば値を参照し、左辺値として書けば値の代入となる。
std::list<int> lst{1, 2, 3};
auto itr = lst.begin(); // 最初の要素を指すイテレータ
std::cout << *itr; // itr は最初の要素を指しているので 1 を表示
*itr = 9; // 最初の要素を 9 に変更
list オブジェクトが保持する全ての要素を表示するには、以下のように記述する。
std::list<int> lst;
for(auto itr = lst.begin(); itr != lst.end(); ++itr) {
std::cout << *itr << "\n";
}
このような書き方は非常によく出てくるので、イディオムとして覚えておいて欲しい。
※ list のイテレータは大小比較できないので、itr < lst.end() とは書けない。
itr を ix 番目のデータに移動するには、「itr = lst.begin();」で先頭データを指すようにしたのち、「++itr;」を ix 回繰り返す。
list のイテレータは通常のポインタの様に「itr += ix;」で一度に移動することは出来ない。
演習問題:
- int 型の要素 {1, 2, 3, 4, 5, 6, 7} を持つ、双方向リスト lst を宣言し、その内容を表示するコードを書きなさい。
- int 型の要素 {1, 2, 3, 4, 5, 6, 7} を持つ、双方向リスト lst を宣言し、その内容を全て0に設定するコードを書きなさい。
- int 型の要素 {3, 3, 3, 3, 3, 3, 3} を持つ、双方向リスト lst を宣言し、3番目の要素を123に書き換えるコードを書きなさい。
- int 型の要素 {3, 3, 3, 3, 3, 3, 3} を持つ、双方向リスト lst を宣言し、最後の要素を123に書き換えるコードを書きなさい。 ただし、begin() を使用せず end() を使用しなさい。
- const list<int> & を引数にとり、その要素をすべて表示する関数 void print(const list<int> &lst) を定義しなさい。
std::list<int> lst{1, 2, 3, 4, 5, 6, 7};
for(auto itr = lst.begin(); itr != lst.end(); ++itr)
std::cout << *itr << "\n";
std::list<int> lst{1, 2, 3, 4, 5, 6, 7};
for(auto itr = lst.begin(); itr != lst.end(); ++itr)
*itr = 0;
std::list<int> lst{3, 3, 3, 3, 3, 3, 3};
auto itr = lst.begin(); // itr は最初の要素を指す
++itr; // itr は 2番目 を指す
++itr; // itr は 3番目 を指す
*itr = 123;
std::list<int> lst{3, 3, 3, 3, 3, 3, 3};
auto itr = lst.end(); // itr は最後の次の要素を指す
--itr; // itr は最後の要素を指す
*itr = 123;
void print(const list<int> &lst)
{
for(auto itr = lst.begin(); itr != lst.end(); ++itr) {
cout << *itr << " ";
}
cout << "\n";
}
要素の追加
- push_front(値) : void
- push_back(値) : void
- insert(イテレータ, 値) : イテレータ
push_front(値) : void
データを先頭に追加するには push_front(値); を使う。
std::list<int> lst; // 空の双方向リストを生成
lst.push_front(987); // 先頭に 987 を追加
push_back(値) : void
データを末尾に追加するには push_back(値); を使う。
std::list<int> lst; // 空の双方向リストを生成
lst.push_back(123); // 末尾に 123 を追加
処理時間は、push_front(), push_back() ともに、O(1) で高速。O(式) は処理時間を表す数学的な記法。「ビッグ・オー記法」と呼ばれる。 O(1) は要素数に依らず常に一定時間で処理出来るという意味で、高速なのだ。
insert(イテレータ, 値) : イテレータ
任意の場所にデータを挿入したい場合は insert(iterator, 値) を使う。
insert(iterator, 値) は、第1引数に挿入する場所へのイテレータを、第2引数に挿入するデータを指定する。
イテレータは先に説明したものだ。ix 番目に挿入するには begin() で先頭を取得し、++itr; を ix 回繰り返す。
そして、insert() は挿入したデータへのイテレータを返す。
注意: insert() を実行すると、コンテナクラスによっては、引数に指定したイテレータが不正になる場合がある。
特に vector では insert() で領域が足りなくなると、メモリをアロケートし直すので、引数に使用したイテレータをその後も使用してはいけない。
なので、insert() が返す値を itr に代入し、itr が正しいデータを指すようにする。
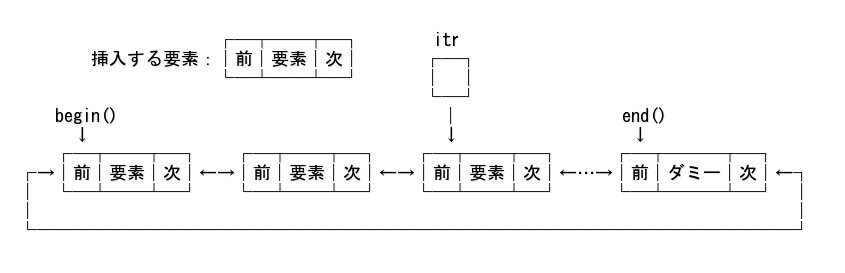
挿入前:
挿入後:
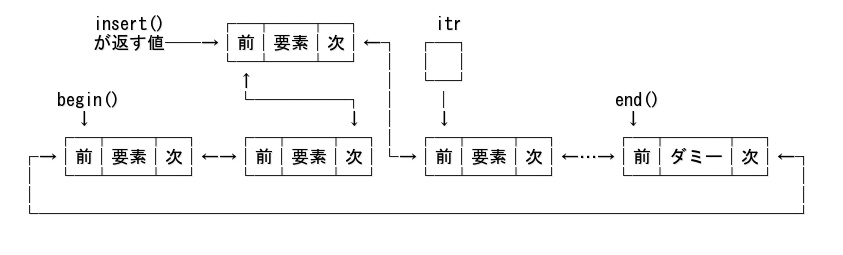
例えば、データの値が 3 だったら、その前に 0 を挿入するコードは以下のようになる。
std::list<int> lst{3, 4, 3, 2, 4, 3, 1};
for(auto itr = lst.begin(); itr != lst.end(); ++itr) {
if( *itr == 3 ) {
itr = lst.insert(itr, 0); // 3 の前に 0 を挿入、itr は 0 を指す
++itr; // itr を 3 の位置に進める
}
}
慣れないと、少し混乱するかもしれないが、デバッガでトレースするなりしてしっかり理解して欲しい。
演習問題:
- 空の int型 list オブジェクトを生成し、末尾に 1 ~ 10 のデータを追加するコードを書きなさい。
- 先に示した 3 の前に 0 を挿入するコードをビルドし、デバッガで動作を確認しなさい。
- 初期値 0 で、10個の int型 list オブジェクトを生成し、[5] の位置に 7 を挿入するコードを書きなさい。
- 空の int型 list オブジェクトを生成し、末尾に 0 のデータを繰り返し追加するコードを書きなさい。 繰り返し回数が 10回、100回、1000回、10000回の場合の処理時間がどの程度かを計測しなさい。
- vector でも上記と同様のコードを書き、処理速度を比較しなさい。
- 空の int型 list オブジェクトを生成し、先頭に 0 のデータを繰り返し追加するコードを書きなさい。 繰り返し回数が 10回、100回、1000回、10000回の場合の処理時間がどの程度かを計測しなさい。
- vector でも上記と同様のコードを書き、処理速度を比較しなさい (ヒント:vector には push_front() が無いので、代わりに insert(v.begin(), val) を使用しなさい)。
std::list<int> lst;
for(int i = 1; i <= 10; ++i)
lst.push_back(i);
std::list<int> lst(10, 0);
auto itr = lst.begin();
for(int i = 0; i < 5; ++i)
++itr; // itr を先頭から5つ進める
lst.insert(itr, 7);
※ 処理時間計測方法が分からない場合は、以下を参照してください。
手を動かしてさくさく理解する C/C++ 処理時間計測 入門
void listPushBack(int n) // n は繰り返し回数
{
std::list<int> lst;
Timer tm;
tm.restart();
for (int i = 0; i < n; ++i) {
lst.push_back(0);
}
auto dur = tm.elapsed();
std::cout << "count = " << n << ", time = " << dur << "\n";
}
int main()
{
cout << "list.push_back():\n";
listPushBack(10);
listPushBack(100);
listPushBack(1000);
listPushBack(10000);
return 0;
}
void vectorPushBack(int n) // n は繰り返し回数
{
std::vector<int> v;
Timer tm;
tm.restart();
for (int i = 0; i < n; ++i) {
v.push_back(0);
}
auto dur = tm.elapsed();
std::cout << "count = " << n << ", time = " << dur << "\n";
}
int main()
{
cout << "vector.push_back():\n";
vectorPushBack(10);
vectorPushBack(100);
vectorPushBack(1000);
vectorPushBack(10000);
return 0;
}
void listPushFront(int n) // n は繰り返し回数
{
std::list lst;
Timer tm;
tm.restart();
for (int i = 0; i < n; ++i) {
lst.push_back(0);
}
auto dur = tm.elapsed();
std::cout << "count = " << n << ", time = " << dur << "\n";
}
int main()
{
cout << "list.push_front():\n";
listPushFront(10);
listPushFront(100);
listPushFront(1000);
listPushFront(10000);
return 0;
}
void vectorPushFront(int n) // n は繰り返し回数
{
std::vector v;
Timer tm;
tm.restart();
for (int i = 0; i < n; ++i) {
v.insert(v.begin(), 0);
}
auto dur = tm.elapsed();
std::cout << "count = " << n << ", time = " << dur << "\n";
}
int main()
{
cout << "vector.push_front():\n";
vectorPushFront(10);
vectorPushFront(100);
vectorPushFront(1000);
vectorPushFront(10000);
return 0;
}
要素の削除
- pop_front() : void
- pop_back() : void
- erase(イテレータ) : イテレータ
pop_front() : void
最初の要素を削除したい場合は pop_front() を用いる。
std::list<int> lst{3, 1, 4, 1, 5};
lst.pop_front(); // 先頭データ(この場合は 3)を削除
pop_back() : void
最後の要素を削除したい場合は pop_back() を用いる。
std::list<int> lst{3, 1, 4, 1, 5};
lst.pop_back(); // 末尾データ(この場合は 5)を削除
pop_front(), pop_back() ともに、処理時間は O(1) と高速である。
erase(イテレータ) : イテレータ
任意の位置の要素を削除したい場合は erase(iterator) を使用する。
std::list<int> lst{3, 1, 9, 4};
auto itr = lst.begin();
++itr;
++itr; // 3番目の要素に移動
lst.erase(itr); // 3番目の要素(9)を削除
erase() は削除した要素の次の要素へのイテレータを返す。
(上記の例だと、消した 9 の次の要素である 4 を指すイテレータを返す)
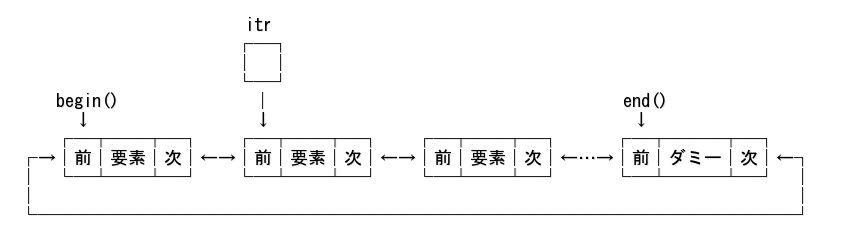
削除処理を図示すると下図の様になる。
削除前:
削除後:
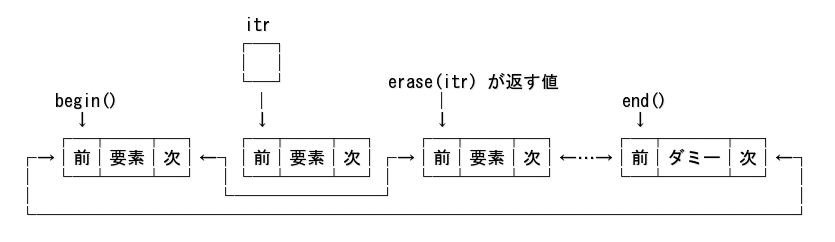
std::vector の様に、削除された場所以降のデータを前にずらすのではなく、ポインタを付け替えるだけだ。 だから、削除処理が、要素数に依らず O(1) と定数時間で可能なのだ。
itr が指していた場所はメモリを管理するヒープ領域に返され、itr が指す先は無効になるので、その後も itr をそのまま使用してはいけない。 その後も itr を使用するのであれば、必ず erase(itr) が返す値を itr に代入し、itr が正しいノードを指すようにしなくてはいけない。
なので、リストに含まれる 1 の要素を全て削除したい場合は、以下のように記述する。
for(auto itr = lst.begin(); itr != lst.end(); ) {
if( *itr == 1 ) // 要素が 1 ならば
itr = lst.erase(itr); // 要素を削除し、itr は次の要素を指す
else
++itr; // itr をひとつ進める
}
演習問題:
- pop_front() で先頭を削除するコードを書き、デバッガで実行し、先頭データが削除されたことを確認しなさい。
- pop_back() で末尾を削除するコードを書き、デバッガで実行し、末尾データが削除されたことを確認しなさい。
- erase() で 3 番目の要素を削除し、本当に削除されたことを確認するコードを書き、実行してみなさい。
- 要素数1万個の std::list<char> lst を作り、lst が空になるまで pop_front() で要素を削除する時間を計測しなさい。 要素数が、10万個、100万個と増えると、処理時間が何倍になるか計測しなさい。
- 上記と同じことを vector で計測し(ヒント:vector には pop_front が無いので v.erase(v.begin())を使用しなさい)、 list の計測結果と比較しなさい。
- list<int>&, int を引数にとり、limit 未満の要素をすべて削除する関数
void eraseLessThan(list<int>& lst, int limit) を定義し、 テストしなさい。
例:limit = 4 の場合:{3, 1, 1, 4, 1, 5, 5, 5, 6} → {4, 5, 5, 5, 6} // 4 未満の要素を削除
例:limit = 7 の場合:{1, 1, 1, 1, 5, 5, 5, 6} → {} // 7 未満の要素を削除 → 空になる
例:limit = 0 の場合:{} → {} // 空のリストでコールしても大丈夫なことを確認するように! - list<int>& を引数にとり、連続する要素が同じ値だった場合は、最初の要素以外を削除する関数 void uniq(list<int>&lst) を定義し、
テストしなさい。
例:{3, 1, 1, 4, 1, 5, 5, 5, 6} → {3, 1, 4, 1, 5, 6} // 1, 5 が連続しているので、最初以外を削除
例:{1, 1, 1, 1, 5, 5, 5, 6} → {1, 5, 6} // 1, 5 が連続しているので、最初以外を削除
例:{} → {} // 空のリストでコールしても大丈夫なことを確認するように!
std::list<int> lst{3, 1, 4, 1};
lst.pop_front();
std::list<int> lst{3, 1, 4, 1};
lst.pop_back();
std::list<int> lst{3, 1, 4, 1};
auto itr = lst.begin();
++itr;
++itr; // 4 まで進める
lst.erase(itr);
for(auto itr = lst.begin(); itr != lst.end(); ++itr) {
std::cout << *itr << "\n";
}
void eraseLessThan(std::list<int> &lst, int limit)
{
for (auto itr = lst.begin(); itr != lst.end(); ) {
if( *itr < limit ) { // 要素が limit 未満ならば
itr = lst.erase(itr); // それを削除、itr は次の要素に移動
} else {
++itr;
}
}
}
void uniq(std::list<int> &lst)
{
auto itr = lst.begin();
if( itr == lst.end() ) return; // lst が空の場合
int prev = *itr++; // 最初の要素は削除されることはない
while( itr != lst.end() ) {
if( *itr == prev ) { // 同じ要素が続く場合
itr = lst.erase(itr); // それを削除
} else {
prev = *itr++;
}
}
}
要素のソート sort
標準アルゴリズムには std::sort(first, last) が用意されているのだが、引数に渡すイテレータはランダム・アクセス可能なものでないといけない。 残念なことに std::list のイテレータはランダム・アクセス可能ではないので、std::sort() を利用することが出来ない。
下記は、ビルド時エラーとなる。
std::list<int> lst= {3, 1, 1, 4, 1, 5, 5, 5, 6};
std::sort(lst.begin(), lst.end()); // ビルド時エラー
それでは困る場合もあるので、sort() が list のメンバ関数として用意されている。
使い方はいたって簡単、sort() を呼ぶだけだ。
std::list<int> lst= {3, 1, 1, 4, 1, 5, 5, 5, 6};
lst.sort();
ただし、注意事項としては、list 要素の型が大小比較できる(operator<() が定義されている)必要がある。 POD や string であれば既に定義されているが、自分で作った型の場合は operator<() をちゃんと定義しよう。
以下は、operator<() が定義されていないのでエラーになる。
class MyClass {
public:
int _a;
};
int main() {
std::list<MyClass> lst;
lst に値を設定;
lst.sort(); // ビルドエラーになる
return 0;
}
下記のように、operator<() を定義してあげるとエラーはなくなる。
class MyClass {
public:
bool operator<(const MyClass &rhs) const
{
return _a < rhs._a;
}
public:
int _a;
};
演習問題:
- list<int> 型のオブジェクトを {3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5} で初期化し、sort() でソートするコードを書きなさい。
- list<string> 型のオブジェクトを {"hoge", "xyzzz", "xyz", "abc", "a"} で初期化し、sort() でソートするコードを書きなさい。
- operaor<() を定義しない MyClass の例をビルドし、エラーが出ることを確認しなさい。
- operaor<() を定義した MyClass の例をビルドし、エラーが出なくなることを確認しなさい。
その他のメンバ関数
ここまで、双方向リストの宣言、値の参照・代入・追加・削除方法について説明した。
それらを使えば、挿入削除処理を高速化したい場合等に、通常配列を双方向リストに置き換えることができるはずだ。
実は双方向リストにはこれまで説明してきたもの以外にも便利な機能がメンバ関数としていくつも用意されている。
配列が空かどうかをチェックしたり、要素数を調べたり、サイズを変更することもできる。
これらは通常配列に対する明らかなアドバンテージである。
オブジェクトの状態を取得
- empty() : bool
- size() : size_t
empty() : bool
「bool empty()」は双方向リストが空かどうかを判定する関数。
std::list<int> lst; に対して、lst.empty() と書くと、lst が空ならば true を、空でなければ false を返す。
次に出てくる size() を使って、size() == 0 と判定するのと同等だ。
が、コンテナクラスによっては size() 計算よりも empty() の方が高速な場合がある。
なので、list などのコンテナクラスに対しては empty() を使うことが推奨されている。
std::list<int> lst;
if( lst.empty() )
std::cout << "empty.\n";
else
std::cout << "not empty.\n";
std::list<int> lst2{1, 2, 3};
if( lst2.empty() )
std::cout << "empty.\n";
else
std::cout << "not empty.\n";
size() : size_t
「size_t size()」は、要素数を返す関数。
通常配列だと「sizeof(data)/sizeof(data[0])」または end(data) - begin(data) のように記述しないと要素数を取得できないが、
list であれば「lst.size()」と簡潔かつ分かりやすく書ける。
※ size_t はサイズを表す型で、符号なし整数の組み込み型である。ちなみに、sizeof() も size_t 型を返す。
std::list<int> lst;
std::cout << lst.size() << "\n"; // 空なので 0 が表示される
std::list<int> lst123{1, 2, 3};
std::cout << lst123.size() << "\n"; // 123 が表示される
オブジェクトの要素を取得
- front() : 要素型
- back() : 要素型
front() : 要素型、back() : 要素型
「front()」は先頭要素の値を返す関数。「*(lst.begin())」と記述するのと同等。
「back()」は末尾要素の値を返す関数。「auto itr = lst.end(); *--itr)」と記述するのと同等。
std::list<int> lst{1, 2, 3};
std::cout << lst.front() << "\n"; // 先頭の 1 が表示される
std::cout << lst.last() << "\n"; // 末尾の 3 が表示される
オブジェクトの状態を変更
- clear() : void
- resize(size_t) : void
- swap(オブジェクト) : void
clear() : void
「clear()」は双方向リストを空にする関数。
サイズを0にする。vector とは違い、要素を delete し、メモリが解放される。
std::list<int> lst{3, 1, 4};
lst.clear(); // 要素をクリア
resize(size_t) : void
「resize(size_t sz)」は要素数を指定サイズに設定する関数。
sz が現在のサイズを超えていれば、型のデフォルト値が格納される。
サイズが増えた部分の値を指定したい場合は、「resize(size_t sz, 値)」と、第2引数で値を指定する。
サイズが減った場合は、要素が delete され、その分のメモリが解放される。
list<int> lst{3, 1, 4, 1, 5};
lst.resize(3);
for(auto x : lst) cout << x << " ";
cout << "\n";
lst.resize(5);
for(auto x : lst) cout << x << " ";
cout << "\n";
swap(オブジェクト) : void
「lst.swap(lst2)」は lst の内容と lst2 の内容を入れ替える。
list<int> lst1{3, 1, 4, 1, 5};
list<int> lst2{9, 8, 7};
lst1.swap(lst2);
cout << "lst1: ";
for(auto x : lst1) cout << x << " ";
cout << "\n";
cout << "lst2: ";
for(auto x : lst2) cout << x << " ";
cout << "\n";
演習問題:
- std::list<int> lst; に対して、empty(), size() をコールし、それぞれの関数が返す値を表示するコードを書きなさい。
- std::list<int> lst{3, 1, 4}; に対して、empty(), size() をコールし、それぞれの関数が返す値を表示するコードを書きなさい。
- std::list<int> lst{3, 1, 4}; に対して、front(), back() をコールし、それぞれの関数が返す値を表示するコードを書きなさい。
- std::list<int> lst{3, 1, 4}; に対して、clear() をコールし、empty(), size() が返す値を表示するコードを書きなさい。
- std::list<int> lst{3, 1, 4}; に対して、resize(8) をコールし、empty(), size()、各要素の値を表示するコードを書きなさい。
- std::list<int> lst{3, 1, 4}; に対して、resize(1) をコールし、empty(), size()、各要素の値を表示するコードを書きなさい。
- std::list<int> lst{3, 1, 4}, lst2{9, 8}; を宣言し、swap で中身を入れ替えるコードを書きなさい。
std::list<int> lst;
cout << lst.empty() << "\n";
cout << lst.size() << "\n";
std::list<int> lst{3, 1, 4};
cout << lst.empty() << "\n";
cout << lst.size() << "\n";
std::list<int> lst{3, 1, 4};
cout << lst.front() << "\n";
cout << lst.back() << "\n";
std::list<int> lst{3, 1, 4};
lst.clear();
cout << lst.empty() << "\n";
cout << lst.size() << "\n";
std::list<int> lst{3, 1, 4};
lst.resize(8);
cout << lst.empty() << "\n";
cout << lst.size() << "\n";
for(auto itr = lst.begin(); itr != lst.end(); ++itr)
cout << *itr << "\n";
std::list<int> lst{3, 1, 4};
lst.resize(1);
cout << lst.empty() << "\n";
cout << lst.size() << "\n";
for(auto itr = lst.begin(); itr != lst.end(); ++itr)
cout << *itr << "\n";
std::list<int> lst{3, 1, 4};
std::list<int> lst2{9, 8};
lst.swap(lst2);
list を関数の引数として渡す
list はクラスなので、list オブジェクトを引数として関数に渡すことが可能です。
例えば、下記の様に list<int> を引数とし、要素の最大値を返す関数を定義することが出来ます。
int max(std::list<int> lst)
{
int maxVal = INT_MIN; // 整数最小値
for(auto itr = lst.begin(); itr != lst.end(); ++itr) {
if( *itr > maxVal )
maxVal = *itr;
}
return maxVal;
}
int main()
{
std::list<int> lst;
lst に要素を追加;
int mx = max(lst);
.....
}
上記関数は正しく動作するのですが、引数の型が実体になっているので、関数コール時にコピーコンストラクタが呼ばれて、
コピーされたオブジェクトが関数に渡されます。
要素数が多い場合、コピーコンストラクタの処理はそれなりに重くなります。
なので、コピーする必然性がなければ、実体ではなく参照渡しにするのが普通です。
int max(std::list<int> &lst)
{
..... // 中身はいっしょ
}
こうしておけば、関数に渡されるのはオブジェクトのアドレスなので、処理時間を要することはありません。
さらに言えば、この場合は、関数の中で要素を修正しないので、const std::list<int> &lst とした方がよいです。
当然ながら、関数内で要素を修正する場合は、const を付けないようにします。
このように、std::list は簡潔な表記で、関数の引数としてオブジェクトを渡すことが可能です。
それに比べ通常配列だと、サイズ情報を保持していないので、引数に要素数または最後のアドレスを指定する必要があります。
この点も std::list が優れているところです。
アルゴリズム
実は C++ には結構便利なアルゴリズムがいくつも用意されている。
参照:http://www.cplusplus.com/reference/algorithm/
ここでは、list に対してよく使うかもしれないアルゴリズムを2つだけ簡単に説明する
- accumulate(first, last, 初期値) : 要素型
- reverse(first, last) : void
accumulate(first, last, 初期値) : 要素型
「accumulate(オブジェクト名.begin(), オブジェクト名.end(), init)」は、双方向リストの最初から最後まで、要素を積算(全加算)するものだ。
最後の引数は初期値で、通常は0を指定する。
なお、accumulate を利用するには「#include <numeric>」が必要。
#include <numeric>
.....
std::list<int> lst{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
std::cout << std::accumulate(lst.begin(), lst.end(), 0) << "\n";
一部を積算したい場合は、「accumulate(first, last, 0)」の様にイテレータで範囲を指定する。
reverse(first, last) : void
「reverse(オブジェクト名.begin(), オブジェクト名.end())」は、コンテナオブジェクトに含まれる要素を逆順にする関数だ。
std::list<int> lst{3, 1, 4};
std::reverse(lst.begin(), lst.end());
for(auto x : lst) std::cout << x << " "; // 4 1 3 と表示される
std::cout << "\n";
演習問題:
- 要素数1万個の双方向リストを作成し、各要素を [0, 99] の範囲でランダムに設定し、accumulate() を使い、それらの合計を求め表示しなさい。
- 上記処理時間を std::vector を使った場合と比較しなさい。
- {1, 2, 3, 4, 5, 6, 7, 8, 9, 10} の要素数10個の双方向リストを作成し、内容を表示したのち、 reverse() で要素を逆順にして、内容を表示しなさい。
#include <numeric>
.....
std::list<int> lst(10000);
for(auto itr = lst.begin(); itr != lst.end(); ++itr)
*itr = rand() % 100;
std::cout << std::accumulate(lst.begin(), lst.end(), 0) << "\n";
#include <numeric>
.....
std::vector<int> lst(10000);
for(auto itr = lst.begin(); itr != lst.end(); ++itr)
*itr = rand() % 100;
std::cout << std::accumulate(lst.begin(), lst.end(), 0) << "\n";
std::list lst{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
for (auto itr = lst.begin(); itr != lst.end(); ++itr) {
std::cout << *itr << " ";
}
std::cout << "\n";
reverse(lst.begin(), lst.end());
for (auto itr = lst.begin(); itr != lst.end(); ++itr) {
std::cout << *itr << " ";
}
std::cout << "\n";
参考
本稿で説明したのは、std::list の基本的な部分のみである。説明していないメソッドもたくさんある。
それらについては以下のサイトなどで勉強してほしい。
通常、std::list はテンプレートライブラリになっており、ソースが公開されている。
ソースを探しだして、読んでみると勉強になるかもしれない。
ただし、かなりレベルが高いコードなので、ちゃんと理解するのはそれなりの能力と知識と経験が必要だ。
上級者でないと無理だ。ちょっと見て理解不能と思ったら、すぐに勇気ある撤退をしよう。
型固定の双方向リスト List を実装する演習問題も用意している。
これをやり遂げれば、list の中身がどうなっているか、ある程度想像がつくようになるので、ぜひ挑戦してみて欲しい。



