C++ 連想配列クラス std::map とは
std::map とは C++ で標準に使用できる便利な連想配列クラスでござるぞ。
「連想配列クラス」とは検索可能なキーと、キーに対応する値の組(ペア)を要素とするコンテナクラスで、
保持している要素から、キーを指定して値を高速に取り出せるクラスのことだ。
例えば、string 型の人名と int 型の年齢を組にした要素を保持しておくと、名前をキーにして年齢を高速に取得することができる。 名前から年齢への写像(mapping)のようなものなので map というクラス名を持つ。 ※ タイトルのところにある画像のように地図(map)という意味ではない。
ちなみに、単純な配列を使ってキーから要素を取得する処理時間は O(N) であるが、map は O(log N) と高速である。 これは map クラスが2分木(実装に依るけど、たいていは赤黒木)で実装されているからだ。
※ O(N) だと要素数が千倍になると処理時間が千倍になる。2分木の O(log N) であれば、要素数が千倍になっても処理時間の増加は約10倍でしかない。 要素数が100万倍になったときの差はもっと顕著だ。
map とよく似たクラスとして、C++11で追加された unordered_map というものもある。
これは ハッシュ
を使っているために、キーから要素を取り出す処理時間が O(1) とさらに高速である。
ただし、unordered_map はその名前の通り、要素が順序付けされていないという欠点があるので、
順序付けが必須の場合は map を使うことになる。
また、ひとつのキーに対応する値を複数持つことが出来る multimap というものもあるぞ。
データ構造
std::map のデータ構造の例を下図に示す。
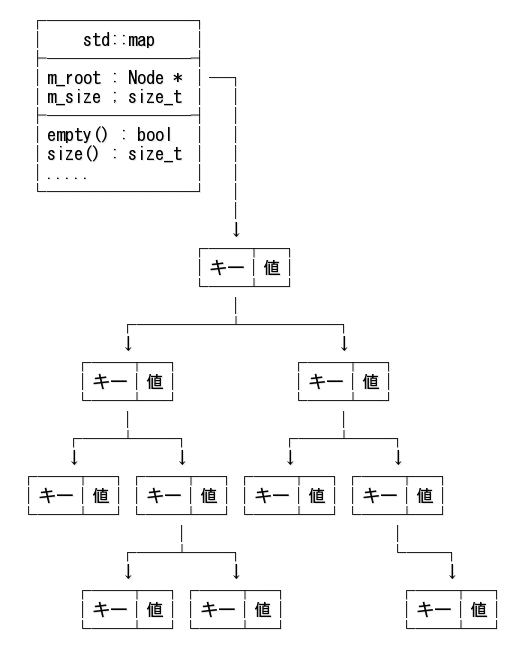
これはデータ構造の一例であり、あなたの環境の実際のデータ構造とは少し違うかもしれない。
重要なことは、以下の3点である。
- 各ノードにはキーと値のペアが入っていて、左右の子供ノードへのポインタを持つ
- 左の子供のキー < キー < 右の子供のキー という条件が成立している
- ノードの深さは概ね等しく、木がバランスしている
上記のおかげで、キーに一致するノードをルートから 二分探索
することが可能になるので、探索速度が O(Log N) と高速になるのだ。
※「二分探索」と聞くと恐れる人もいるかもしれないが、二分探索自体は map クラスが自動でやってくれるので、何も難しいことはないぞ。
準備:インクルード
map は C++標準ライブラリに含まれており、「#include <map>」を記述することで利用可能になる。
名前空間は「std」なので、使用の度に「std::」を前置するか、または「using namespace std;」を記述しておく。
#include <map> // ヘッダファイルインクルード
int main()
{
std::map<std::string, int> mp; // ローカル変数として、mp を生成
.....
}
#include <map> // ヘッダファイルインクルード
using namespace std; // 名前空間指定
int main()
{
map<string, int> mp; // ローカル変数として、mp を生成
.....
}
宣言・初期化
単純な宣言
std::map オブジェクトを生成するには「std::map<キー型, 値型> オブジェクト名;」 と記述する。
オブジェクト名とは、宣言する連想配列を識別するための名前のことだ。変数名と言ってもよい。
map はクラスなので、それを実体化したものはオブジェクトまたはインスタンスと呼ばれる。
map が vector や list 等の通常コンテナクラスと異なるのは、コンテナに入る要素の型を2つ指定するところだ。
最初の型はキーとなるものの型で、string や int 型などいろいろな型を指定できる。
ただし、どんな型でも指定できるかというとそうではなく、ノードをキー順に並べるために、キーオブジェクトの順序が計算可能でないといけない。
具体的には bool operator<() が定義されていないとキーの型には指定できない。
例えば、下記のような Person クラスの場合、oprerator<() が定義されていないので、エラーとなる。
struct Person {
public:
Person(const string &name, int height)
: m_name(name)
, m_height(height)
{}
public:
string m_name;
int m_height;
};
.....
map<Person, int> mp; // Person には比較演算子が定義されていないのでエラーになる
Person p("aaa", 170);
mp[p] = 123;
エラーを無くすには、以下のように、比較演算子を定義しておくとよい。
// 比較演算子の定義
bool operator<(const Person &lhs, const Person &rhs)
{
return lhs.m_name < rhs.m_name;
}
値型の方には特に条件は無い。
下記は、string 型をキーとし、int 型を値とする連想配列 mp を宣言している例だ。
std::map<std::string, int> mp; // string → int の連想配列 mp の宣言
このようにして宣言したオブジェクトの要素数は 0、つまり空だ。要素を追加する方法は次の章で説明する。
< > は何だ?と思う人もいるかもしれない。これはC++のテンプレートという機能を使うための記法だ。
テンプレートを完全に理解するのは難易度が高いので、深く理解しようとすると先に進めなくなる。
深入りはせず、現在のところはキーと値の型をこういう書き方で指定すると無条件で覚えてほしい。
コピーコンストラクタ
コピーコンストラクタとは、同じ型のオブジェクトを渡され、それと同じ内容のオブジェクトを生成するコンストラクタのことである。
「std::map<キー型, 値型> オブジェクト名(コピー元オブジェクト名);」と記述する。
当然ながら、コピー元オブジェクトと生成するオブジェクトは通常同じ型である必要がある。
※ 暗黙の型変換が可能な型であれば、コピー元オブジェクトとして指定可能ではある。
std::map<std::string, int> org;
org に要素を追加
std::map<std::string, int> x(org); // コピーコンストラクタ
上記のコードは org をコピーし、同じ値を持つ連想配列 x を生成する。
演習問題:
- キー型 std::string, 値型 char の連想配列 mp を宣言しなさい。
- キー型 int, 値型 double の連想配列 mp を宣言しなさい。
- キー型 std::string, 値型 std::string の連想配列 mp を宣言しなさい。
std::map<std::string, char> mp;
std::map<int, double> mp;
std::map<std::string, std::string> mp;
値の設定、参照
キーに対応する値の設定
連想配列にキーに対する値を設定するには「mp[キー] = 値;」と記述する。
例えば、std::map<std::string, int> mp に対し、キー"abc" の値を 123 に設定するには、以下のように記述する。
std::map<std::string, int> mp; // 文字列 → 整数 の連想配列
mp["abc"] = 123;
この書き方は直感的にわかりやすく便利でしょ。
設定した値は何度でも上書きすることが出来る。
mp["abc"] = 123;
mp["abc"] = 456;
mp["abc"] = 789;
上記の様に mp["abc"] の値を複数回設定した場合は、最後に設定した値が有効になる。
キーに対応する値を設定すると、map が持つツリーにキーと値のペアが追加される。追加処理に要するコストは、要素数を N として、O(Log N) である。 これはN個のデータを全て追加するコストが N * O(Log N) = O(N * Log N) であることを意味する。 通常、一連の操作で許される処理時間は O(N * Log N) までなので、充分高速な処理速度ということだ。
キーに対応する値の取得
右辺値として mp[キー] と記述することで、mp から キー を検索し、その値を取得することが出来る。
例えば、前節のように mp["abc"] に 123 が設定されているとき、mp["abc"] は 123 を返す。
値が設定されていないキーを指定した場合、値型のデフォルト値が返される。
std::map<std::string, int> mp;
mp["Lotus"] = 123;
std::cout << mp["Lotus"] << "\n"; // mp["Lotus"] の値 123 が表示される
std::cout << mp["IBM"] << "\n"; // mp["IBM"] は設定されていなかったので、0 が表示される
実は [] 演算子「operator[]()」が返す型は、右辺値であっても(非const な)値への参照である。したがって、連想配列が保持していないキーを使うと、 そのキーとデフォルト値のノードが作成されてしまうので、留意してほしい。
なので、const 型の連想配列に対しては [] 演算子を使うことは出来ない。
std::map<std::string, int> mp;
mp["Lotus"] = 123;
const std::map<std::string, int> mp2(mp); // const(変更不可)な mp2 を生成
cout << mp2["Lotus"] << "\n"; // 右辺値なのにエラーとなる
上記の様に作った様な例ではなく、関数引数として const な連想配列を渡すことはよくある。そのような場合に [] 演算子は使用できないので注意だ。
連想配列が const の場合に値を参照したい場合は at(キー) メンバ関数を使う。この関数は const 型も定義されているので大丈夫だ。
std::map<std::string, int> mp;
mp["Lotus"] = 123;
const std::map<std::string, int> mp2(mp); // mp を元にして const(変更不可)な mp2 を生成
cout << mp2.at("Lotus") << "\n"; // 123 が表示される
個人的には at() よりも [] 演算子の方が好きなので、なぜ [] 演算子が const 対応していないのか理解に苦しむ。 対応が技術的に難しいとは考えられないので、将来的は const 対応の [] 演算子が導入されると思う。
データ構造のところでも述べたように、キーを探すコストは、要素数を N として O(Log N) である。
ノードが勝手に作成されないように、値が本当に設定されているかどうかを確認するには、次章で説明する検索機能を使用する。
全てのキー・値の取得
mp を map オブジェクトとすると、mp.begin() で最初の要素へのイテレータを、mp.end() で最後の要素の次へのイテレータを取得できる。
要素はキーと値のペア(std::pair)のことで、キー・値それぞれを itr->first, itr->second で取得できる。
下記は、連想配列の最初から最後までをイテレータを回し、要素の内容を表示する例だ。
std::map<std::string, int> mp
いろんな値を設定;
for(auto itr = mp.begin(); itr != mp.end(); ++itr) {
std::cout << "key = " << itr->first // キーを表示
<< ", val = " << itr->second << "\n"; // 値を表示
}
ちなみに、イテレータを進めるのに要するコストは O(1) である。よって、最初から最後までイテレータを進めるのに要するコストは 要素数を N とすると、O(1) * N = O(N) となる。
演習問題:
- キー、値ともに文字列型の連想配列 mp を宣言し、"aiueo" の値を "123" に、"kakikukeko" の値を "9876" に設定しなさい。
- 文字列をキー、整数を値とする連想配列 mp を宣言し、"aiueo" の値を 1 に、"kakikukeko" の値を 2 に設定しなさい。
- 上記 mp に対し、mp["aiueo"], mp["kakikukeko"], mp["sashisuseso"] の値を表示するコードを書きなさい。
- 連想配列、値を引数にとり、連想配列に値が含まれるかどうかをチェックする関数
bool isContained(const std::map<std::string, int> &, int val) を定義しなさい。
文字列をキー、整数を値とする連想配列 mp を宣言し、mp["aiueo"] = 1; mp["kakikukeko"] = 2; を実行後に、 isContained(mp, 0) は false を、isContained(mp, 1) は true を、isContained(mp, 2) は true を、isContained(mp, 3) は false を返すことを確認しなさい。 - キー、値ともに int 型の連想配列 mp を宣言し、キー・値をランダムに生成し100個のペアを mp に追加しなさい。 その後、mp に格納されている要素を begin() から end() まで表示し、キーが昇順に並んでいることを確認しなさい。
- キー、値ともに int 型の連想配列 mp を宣言し、キー・値をランダムに生成し1万個のペアを mp に追加するのに要する時間を計測しなさい。 追加する要素数を 10万個、100万個とした場合の処理時間も計測・比較し、ひとつのペアを連想配列に追加するコストが O(log N) であることを確認なさい。
std::map<std::string, std::string> mp;
mp["aiueo"] = "123";
mp["kakikukeko"] = "9876";
std::map<std::string, int> mp;
mp["aiueo"] = 1;
mp["kakikukeko"] = 2;
std::cout << mp["aiueo"] << "\n";
std::cout << mp["kakikukeko"] << "\n";
std::cout << mp["sashisuseso"] << "\n";
bool isContained(const std::map<std::string, int> &, int val)
{
for(auto itr = mp.begin(); itr != mp.end(); ++itr) {
if( itr->second == val ) // 値を発見した場合
return true;
}
return false; // 値が発見できなかった場合
}
std::map<int, int> mp;
const int N = 100;
for(int i = 0; i < N; ++i) {
mp[rand()] = rand();
}
for (auto itr = mp.begin(); itr != mp.end(); ++itr) {
std::cout << itr->first << ": " << itr->second << "\n";
}
#include <chrono>
void measure(int N)
{
std::cout << N << ":";
const int RAND_UPPER = 10000; // 乱数値上限
map<int, int> mp;
auto start = std::chrono::system_clock::now(); // 計測スタート時刻を保存
for (int i = 0; i < N; ++i) {
mp[rand() % RAND_UPPER] = rand() % RAND_UPPER; // [0, 9999]
}
auto end = std::chrono::system_clock::now(); // 計測終了時刻を保存
auto dur = end - start; // 要した時間を計算
// 要した時間をミリ秒(1/1000秒)に変換して表示
std::cout << std::chrono::duration_cast<std::chrono::milliseconds>(dur).count() << " milli sec \n";
}
int main()
{
measure(10000);
measure(100000);
measure(1000000);
}
キーの検索
find(キー) : イテレータ
mp を map オブジェクトとすると、mp.find(キー) で、キーが mp に設定されているかどうかを調べることが出来る。
キーが設定されている場合は、キーと値のペアへのイテレータを返す。
キーが設定されていない場合は、end() へのイテレータを返す。
std::map<std::string, int> mp
いろんな値を設定;
auto itr = mp.find("xyz"); // "xyz" が設定されているか?
if( itr != mp.end() ) {
設定されている場合の処理
} else {
設定されていない場合の処理
}
キーと値のペアとは std::pair<キー型, 値型> のことである。なので、キーは itr->first, 値は itr->second で取得することが出来る。
auto itr = mp.find("xyz");
if( itr != mp.end() ) {
cout << itr->first << "\n"; // "xyz" が表示される
cout << itr->second << "\n"; // mp["xyz"] の値が表示される
}
itr が end() でない場合は、「itr->second = 値;」で、値を書き換えることも出来るぞ。
lower_bound(キー) : iterator
lower_bound(キー) は、引数で指定されたキー以上のキーを持つ最初のノードへのイテレータを返す。
例えば、キー型が文字列、値型が整数の連想配列 mp があり、mp["a"] = 1; mp["b"] = 2; mp["x"] = 10; が設定されているとき、
lower_bound("b") は、("b", 2) のペアへのイテレータを返す。
lower_bound("c") は、("x", 10) のペアへのイテレータを返す。
lower_bound("z") は、end() を返す。
upper_bound(キー) : iterator
upper_bound(キー) は、引数で指定されたキーより大きいキーを持つ最初のノードへのイテレータを返す。
例えば、キー型が文字列、値型が整数の連想配列 mp があり、mp["a"] = 1; mp["b"] = 2; mp["x"] = 10; が設定されているとき、
upper_bound("b") は、("x", 10) のペアへのイテレータを返す。
upper_bound("c") は、("x", 10) のペアへのイテレータを返す。
upper_bound("z") は、end() を返す。
lower_bound(キー), upper_bound(キー) は次章で出てくる erase(first, last) で範囲削除を行うときに使うことが出来る。
演習問題:
- キー型:文字列、値型:int のマップを生成し、"abc" の値を 1 に、"xyz" の値を 9 に設定し、それぞれを検索し結果が正しいことを確認しなさい。
- 上記マップに対し "aiueo" を検索し、結果が正しいことを確認しなさい。
- 上記マップに対し、"xyz" を検索し、検索結果を使ってその値を 10 に書き換えなさい。
std::map<std::string, int> mp;
mp["abc"] = 1;
mp["xyz"] = 9;
auto itr = mp.find("abc");
if( itr != mp.end() && itr->first == "abc" && itr->second == 1 )
std::cout << "OK\n";
else
std::cout << "NG\n";
itr = mp.find("xyz");
if( itr != mp.end() && itr->first == "xyz" && itr->second == 9 )
std::cout << "OK\n";
else
std::cout << "NG\n";
itr = mp.find("aiueo");
if( itr == mp.end() )
std::cout << "OK\n";
else
std::cout << "NG\n";
itr = mp.find("xyz");
if( itr != mp.end() )
itr->second = 10;
要素の削除
erase(キー) : size_t
mp から、キー:"abc" の要素を削除したい場合は mp.erase("abc") とすればよい。直感的で簡単だ。
存在しないキーを指定した場合は、無視され何も起こらない。
erase(キー) は削除した要素数を返す。map() は重複キーを許さないので、0 または 1 を返す。
erase(イテレータ) : イテレータ
予め、キーが存在しているかどうかをチェックし、存在している場合のみ削除したい場合は、 以下のように find() でキーが存在することを確認してから、erase(イテレータ) を使用する。
auto itr = mp.find("abc");
if( itr != mp.end() ) // キーの要素が存在している場合
mp.erase(itr);
実はイテレータには end() を指定しても何も問題は起こらない。なので、単に mp.erase(mp.find("abc")); と書いてもいいのだが、 そう書くくらいなら mp.erase("abc") と書いた方が素直で好感が持てる。
erase(first, last) : イテレータ
前節の erase(イテレータ) はひとつのノードしか消すことが出来ないが、erase(first, last) を使えば [first, last) の範囲のノードを一度に消すことが出来る。
キー1からキー2までのノードを削除したい場合は以下のように、lower_bound(), upper_bound() を使うといいぞ。
std::map<std::string, int> mp;
mp に要素を格納;
mp.erase(lower_bound("i"), upper_bound("k")); // キーが "i" から "k" までのノードを全て削除
演習問題:
- キー型:文字列、値型:int のマップを生成し、"abc" の値を 1 に、"xyz" の値を 9 に設定したのち、erase(キー) により "abc" の要素を削除し、 それが正しく削除されたことを確認しなさい。
- キー型:文字列、値型:int のマップを生成し、"abc" の値を 1 に、"xyz" の値を 9 に設定したのち、erase(イテレータ) により "abc" の要素を削除し、 それが正しく削除されたことを確認しなさい。
std::map<std::string, int> mp;
mp["abc"] = 1;
mp["xyz"] = 9;
mp.erase("abc");
for(auto itr = mp.begin(); itr != mp.end(); ++itr) {
cout << "mp[" << itr->first << "] = " << itr->second << "\n";
}
std::map<std::string, int> mp;
mp["abc"] = 1;
mp["xyz"] = 9;
auto itr = mp.find("abc");
mp.erase(itr);
for(auto itr = mp.begin(); itr != mp.end(); ++itr) {
cout << "mp[" << itr->first << "] = " << itr->second << "\n";
}
その他のメンバ関数
オブジェクトの状態を取得
- empty() : bool
- size() : size_t
empty() : bool
「bool empty()」はマップが空かどうかを判定する関数。
次に出てくる size() を使って、size() == 0 と判定するのと同等だ。
が、コンテナクラスによっては size() 計算よりも empty() の方が高速な場合がある。
なので、コンテナクラスに対しては empty() を使うことが推奨されている。
std::map<std::string, int> mp;
if( mp.empty() )
std::cout << "empty.\n";
else
std::cout << "not empty.\n";
mp["abc"] = 123;
if( mp.empty() )
std::cout << "empty.\n";
else
std::cout << "not empty.\n";
size() : size_t
「size_t size()」は、要素数を返す関数。
通常配列だと「sizeof(data)/sizeof(data[0])」のように記述しないと、要素数を取得できないが、
map では「mp.size()」と簡潔かつ分かりやすく書ける。
※ size_t はサイズを表す型で、符号なし整数の組み込み型である。ちなみに、sizeof() も size_t 型を返す。
std::map<std::string, int> mp;
std::cout << mp.size() << "\n"; // 空なので 0 が表示される
mp["abc"] = 123;
mp["xy"] = 99
std::cout << mp.size() << "\n"; // 2 が表示される
オブジェクトの状態を変更
- clear() : void
clear() : void
「clear()」はマップを空にする関数。
サイズを0にする。vector とは違い、要素を delete し、メモリが解放される。
std::map<std::string, int> mp;
std::cout << mp.size() << "\n"; // 空なので 0 が表示される
mp["abc"] = 123;
mp["xy"] = 99
std::cout << mp.size() << "\n"; // 2 が表示される
mp.clear();
std::cout << mp.size() << "\n"; // 空なので 0 が表示される
演習問題:
- std::map<std::string, int> mp; に対して、empty(), size() をコールし、それぞれの値を表示するコードを書きなさい。
- 上記 mp に対し、mp["abc"] = 123; mp["xyz"] = 987; を実行後に empty(), size() をコールし、それぞれの値を表示するコードを書きなさい。
- 上記実行後に mp.clear() を実行し、empty(), size() をコールし、それぞれの値を表示するコードを書きなさい。
std::map<std::string, int> mp;
std::cout << mp.empty() << "\n";
std::cout << mp.size() << "\n";
mp["abc"] = 123;
mp["xyz"] = 987;
std::cout << mp.empty() << "\n";
std::cout << mp.size() << "\n";
mp.clear();
std::cout << mp.empty() << "\n";
std::cout << mp.size() << "\n";
参考
本稿で説明したのは、std::map の基本的な部分のみである。説明していないメソッドもたくさんある。
それらについては以下のサイトなどで勉強してほしい。
通常、std::map はテンプレートライブラリになっており、ソースが公開されている。
ソースを探しだして、読んでみると勉強になるかもしれない。
ただし、かなりレベルが高いコードなので、ちゃんと理解するにはそれなりの能力と知識と経験が必要だ。
上級者でないと無理だ。ちょっと見て理解不能と思ったら、すぐに勇気ある撤退をしよう。