
技術文章>テキストエディタ実装技術その2
テキストエディタのためのバッファの各種データ構造について述べ、
それらを筆者がC++で STLに準じたインタフェースを持つテンプレートクラスとして実装したものについて、
パフォーマンス(処理速度、使用メモリ量)計測を行った結果を報告する。
筆者が実際にテキストエディタを実装する場合にどのデータ構造がよいか、という視点で評価を行う。
目次:
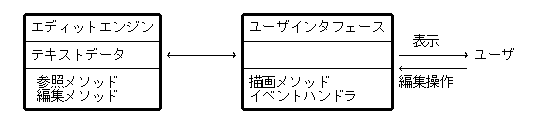
テキストエディタは、簡単に言うと、シーケンシャルなテキスト情報を保持し、ユーザの指示により内容を表示、修正するプログラムである。
上図のような構造はオブジェクト指向な設計と親和性が高い。
テキストデータをメンバ変数に持ち、データを参照、変数するメソッドを持つオブジェクトと、
ユーザの指示を解釈し、適切なメソッドを呼び出すオブジェクトを導入するとよい。
前者をエディットエンジン、後者をUIオブジェクトと呼ぶ。
実在のテキストエディタは vi, Emacs コマンドなど特有のコマンド系を持つが、それらはすべてUIオブジェクトで処理される。
エディットエンジンはコマンド系とは独立で、基本的な編集機能を持つものである。。
テキストエディタにおいて、文字のシーケンシャルデータ(データが1次元に並んだもの) を管理するものをバッファと呼ぶ
下図に初期のViViのバッファまわりのクラス図を示す。

バッファはテキストエディタの最も基本となる部分なので、必要充分な機能・高信頼性・高速性・メモリ効率の良さ・拡張性 が求められる。
バッファのデータ構造には様々なものがあり、それぞれ一長一短がある。
本稿では(筆者が知っている)バッファの各種データ構造・実装について述べ、VC9 で実装したクラスのパフォーマンス計測を行い、それらの評価を行う。
テキストエディタ用バッファに要求される基本機能:
置換やバッファ全体に対する検索機能などは、上記の基本機能を利用して実装することができる。
ファイルをオープンした場合、ファイル内容をバッファに読み込むので、バッファ構築時間と、メモリ使用量が問題となる。
当然、構築時間が短いほど、メモリ使用量が少ないほどよい。破棄に時間がかかるのも好ましくない。 バッファへの一括読み込みは、編集の挿入機能を繰り返してもよいが、ファイル読み込み時の待ち時間を最小化し、
使用メモリ量を減らすために、バッファ構築機能を基本機能に加えておいた方がよいと考える。
当然ながら、バッファに保持したテキストをクラス外から参照可能でなくてはいけない。
行単位のエディタであれば、行番号を指定してその行のテキストを取得できるとよい。
文字単位の参照のために文字イテレータがあるとよい。
文字イテレータを実装しておけば STL/boost の豊富なアルゴリズムを直接利用することができる。
編集の基本操作は、挿入と削除である。 本稿でも、バッファクラスインタフェースを真っ先に決める。バッファに要求される機能・性能
バッファ構築
近年はファイルサイズが巨大になってきているので、すべて読み込むのに時間がかかりすぎたり、メモリに入りきらない場合がある。
バックグラウンドで読み込みを行ったり、メモリにすべて読み込むのではなく必要な分だけ読み込んで処理ができるとよい。
テキスト参照
class CLineMgr
{
.....
public:
bool getLineText(int lineNum, CString&); // 指定行番号(1..*)の文字列を CString に返す
cchar *getLineText(int lineNum, int &length); // 指定行番号(1..*)の文字列を返す
.....
};
template<trypename CharType>
class CEditBuffer
{
gap_vector<CharType> m_buffer;
.....
public:
gap_vector<CharType>::const_iterator begin() const { return m_buffer.begin(); }
gap_vector<CharType>::const_iterator end() const { return m_buffer.end(); }
.....
}
CEditBuffer eb;
....
int sum = std::accumulate(eb.begin(), eb.end(), 0); // 全文字コードの合計計算
CEditBuffer::iterator itr = std::find(eb.begin(), eb.end(), 'X'); // 文字 'X' を検索
.....
編集(挿入・削除)
挿入・削除ができれば、置換、undo/redo、左右シフトなどの処理は基本メソッドを利用して実装できる。
struct STextPos
{
int m_line; // 行番号(1..*)
int m_offset; // 行内オフセット(0..*)
};
class CLineMgr
{
.....
public:
bool insert(const STextPos&, const CString&);
bool erase(const STextPos&, const STextPos&);
....
};
バッファクラスのインタフェース
第二の機会の法則(Low of Second Chance):正しく理解するために最も大切なのは、インタフェースである。
他のことは後でも直せる。インタフェースを間違えると、それを直す次の機会は無い。
[Sutter04](訳文は C++ Coding Standards より)
インタフェースはデータ構造に依存しないようにし、
利用側プログラムを最小限度書き換えるだけで、他のデータ構造に置き換え可能になるようにする。
理解しやすく、使いやすく、効率的で、実装・拡張が容易なインタフェースが理想。
edit のバッファインタフェース("Software Tools", 1976, pp286-287 より)
バッファの実際の作りをプログラムの他の部分からできるだけ切り離すことが大切である。
そのようにしておけば、下位のバッファ処理ルーチンを多少変更するだけのことで、
与えられた基本方針のもとで能率向上をはかることができるのみならず、
方針自体をすっかり変更することさえ可能である。
| setbuf() : void | バッファ初期化 |
| clrbuf() : void | バッファ内容クリア |
| inject(lin) : status | 文字配列 lin の内容をバッファ現在行直後に転送 (現在行の行番号はグローバル変数 curlin : int が保持) |
| getind(n) : Node* | 行番号nのノード取得 |
| gettxt(n) : void | 行番号nの内容をtxtに転送(txt はグローバルな文字列配列) |
| relink(k1, k2, k3, k4 : Node*) : void | リンクつなぎ替え(行削除、行挿入に使用される) |
Domains:
Syntax:
※ Data Structures for Text Sequences (1995) より
※ Data Structures for Text Sequences (1995) より
データ構造によらず、インタフェースを共通化したクラスを実装
インタフェースは原則 STL のコンテナクラスに準じたものとする。
利点:
欠点:
以下に本稿で計測に用いたクラスのインタフェースを示す。
// 文字イテレータ
template<typename CharType>
class _edit_buffer_char_iterator : public std::iterator<std::bidirectional_iterator_tag, CharType>
{
..... // 文字イテレータ用データ
public:
_edit_buffer_char_iterator(...);
_edit_buffer_char_iterator(const _edit_buffer_char_iterator&); // コピーコンストラクタ
_edit_buffer_char_iterator &operator=(const _edit_buffer_char_iterator &x); // 代入演算子
CharType &operator*(); // dereference
_edit_buffer_char_iterator &operator++(); // インクリメント
_edit_buffer_char_iterator &operator--(); // デクリメント
bool operator==(const _edit_buffer_char_iterator &x); // 等値比較
bool operator!=(const _edit_buffer_char_iterator &x); // 等値比較
};
// 行イテレータ
template<typename CharType>
class _edit_buffer_line_iterator : public std::iterator<std::bidirectional_iterator_tag, CharType>
{
..... // 行イテレータ用データ
public:
_edit_buffer_line_iterator(...);
_edit_buffer_line_iterator(const _edit_buffer_line_iterator&);
.....
_edit_buffer_char_iterator begin(); // 行の最初の文字へのイテレータを返す
_edit_buffer_char_iterator end(); // 行の最後の文字の次へのイテレータを返す
};
template<typename CharType>
class edit_buffer
{
// Container m_buffer;
public:
edit_buffer(); // デフォルトコンストラクタ
edit_buffer(const edit_buffer &); // コピーコンストラクタ
~edit_buffer(); // デストラクタ
edit_buffer &operator=(const edit_buffer &); // 代入演算子
public:
typedef _edit_buffer_char_iterator char_iterator;
char_iterator char_begin(); // 最初の文字へのイテレータを返す
char_iterator char_end(); // 最後の文字の次へのイテレータを返す
public:
typedef _edit_buffer_line_iterator line_iterator;
line_iterator line_begin(); // 最初の行へのイテレータを返す
line_iterator line_end(); // 最終行の次へのイテレータを返す
public:
bool empty() const; // バッファが空か?
size_t char_size() const; // 文字数(0..*)を返す
size_t line_size() const; // 行数(1..*)を返す
public:
void clear(); // バッファ初期化
template<typename InputIterator>
void assign(InputIterator first, InputIterator last); // バッファへ代入
char_iterator erase(char_iterator); // 1文字削除、次の文字へのイテレータを返す
char_iterator insert(char_iterator, CharType); // 1文字挿入、挿入文字へのイテレータを返す
};
基本的に vector 等と同じインタフェース
文字イテレータ、行イテレータであることを強調するために、iterator → char_iterator, line_iterator とした。
insert() が挿入した文字へのイテレータを返すのは STL 互換のため。
イテレータを文字カーソルと考えれば、挿入文字の次を返す方が自然かもしれない。
→ 別メソッドを導入する?
上記はパフォーマンス計測を行うための最小限のインタフェースであり、 実際にエディタを実装する場合は、範囲削除・文字列挿入・置換・undo/redo などのメソッドを追加した方がいいかもしれない。
以下に、上記クラスインタフェースの使用例を示しておく。
ファイル読み込み:
BOOL CMyEditorDoc::OnOpenDocument(LPCTSTR lpszPathName)
{
vector<char> buf;
vector<wchar_t> wbuf;
lpszPathName をオープンし、buf に読み込む。
文字コードを Unicode に変換し、buf -> wbuf 転送。
CEditEngine *editEngine = getEditEngine();
editEngine->assign(wbuf.begin(), wbuf.end());
}
画面描画:
void CMyEditorView::OnDraw(CDC* pDC)
{
const CEditEngine *editEngine = getEditEngine();
int y = 0; // 表示座標
for(CEditEngine::line_iterator li = 画面最上行, liend = editEngine->line_end();
y が画面内 && li != liend;
++li, y += 行高)
{
1行表示(pDC, y, li);
}
}
void CMyEditorView::1行表示(CDC* pDC, int y, const CEditEngine::line_iterator &li)
{
int x = 0;
CDrawTokenizer tn(li->begin(), li->end());
for(CDrawTokenizer::iterator itr = tn.begin(), iend = tn.end();
xが画面右を越えていない && itr != iend; ++itr)
{
*itr を表示;
x += 表示幅(*itr);
}
}
ちなみに これ は昔書いたコード。
1文字挿入、Delete
class CMyEditorView {
CEditEngine::char_iterator m_cursor; // カーソル位置
.....
};
void CMyEditorView::OnChar(UINT nChar, UINT nRepCnt, UINT nFlags)
{
CEditEngine *editEngine = getEditEngine();
m_cursor = editEngine->insert(m_cursor, nChar); // カーソル位置文字挿入
++m_cursor; // カーソル位置補正
Invalidate(); // 画面無効化
}
void CMyEditorView::OnEditDelete()
{
CEditEngine *editEngine = getEditEngine();
m_cursor = editEngine->erase(m_cursor); // カーソル位置文字消去
Invalidate(); // 画面無効化
}
O(1) < O(logN) < O(N) < O(N logN) < O(N^2) < … < O(e^N)
同じアルゴリズムでも、実装方法・コンパイラにより速度は異なり、各アルゴリズムの優劣が逆転する場合がある。
実装し、計測してみることが肝要
Rule 2. Measure. Don't tune for speed until you've measured, and even then don't unless one part of the code overwhelms the rest. (計測すべし。計測するまでは速度のための調整をしてはならない。 コードの一部が残りを圧倒しないのであれば、なおさらである。)Notes on Programming in C Complexity, Rob Pike, 1989 (訳は wikipedia)より
以下の計測を行う
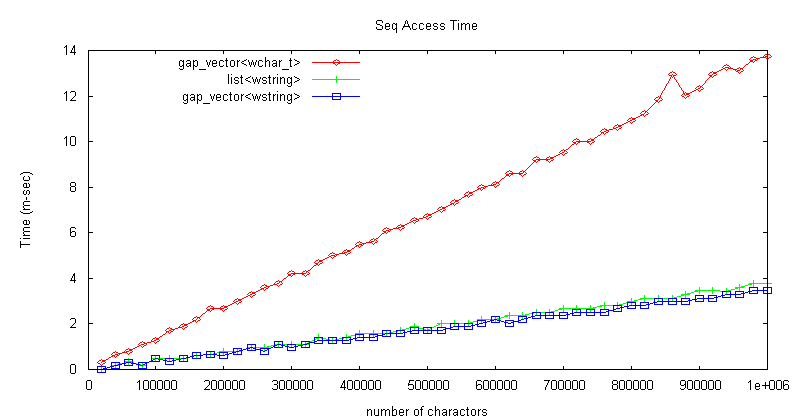
テキスト参照処理の大部分はシーケンシャルアクセス
The number of ItemAt calls that were sequencial (one way from the last ItemAt) was always above 97% and usually above 99%. The number of ItemAt that were within 20 items of the previous ItemAt was always over 99%. The average number of characters from one ItemAt to the next was typically around 2 but sometimes would go up to as high as 10 or 15. Overall these experiments verify that the position of ItemAt calls are extremely localized.
※ Data Structures for Text Sequences より
処理時間が問題となるのは大域的な編集処理の場合である。
位置による処理時間の偏りを避けるため、シーケンシャルアクセスを行いながら削除・挿入を行う時間を計測する。
文字コードは Unicode とする。
C2D(ウルフデール) 3Ghz, 4GMem, WinXP, VC9
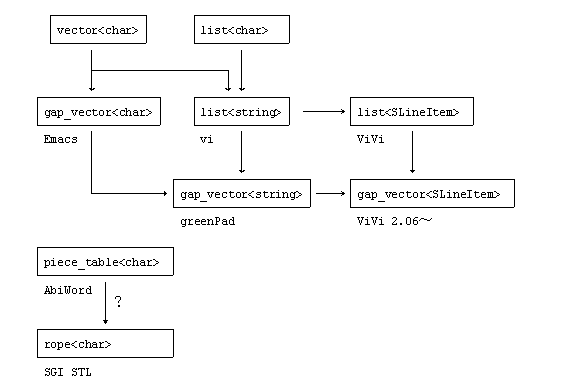
本稿&次稿で取り上げるデータ構造の一覧を下表、下図に示す。
// バッファ構築時間計測
template< typename TEditBuffer, typename InputIterator >
void measure_construct(InputIterator first, InputIterator last, int unit = 10000)
{
TEditBuffer eb;
InputIterator e = first;
const int beg = 2;
const int step = 2;
for(int i = beg; i <= 100; i += step) {
cout << i * unit << " ";
e = find_nth(e, last, '\n', unit * step);
boost::timer tm;
eb.assign(first, e); // 構築
cout << tm.elapsed() << "\n";
}
}
// バッファ構築時使用メモリ計測
template< typename TEditBuffer, typename InputIterator >
void measure_construct_memory(InputIterator first, InputIterator last, int unit = 10000)
{
TEditBuffer eb;
size_t mem0 = get_used_memory_size();
InputIterator e = first;
const int beg = 2;
const int step = 2;
for(int i = beg; i <= 100; i += step) {
cout << i * unit << " ";
e = find_nth(e, last, '\n', unit * step);
eb.assign(first, e); // 構築
size_t mem = get_used_memory_size();
cout << mem - mem0 << "\n";
}
}
// シーケンシャルアクセス時間計測
template< typename TEditBuffer, typename InputIterator >
void measure_seq_access(InputIterator first, InputIterator last, int unit = 10000)
{
TEditBuffer eb;
eb.assign(first, last); // 構築
const int beg = 2;
const int step = 2;
for(int i = beg; i <= 100; i += step) {
int N = i * unit;
cout << N << " ";
boost::timer tm;
const int loop = 100;
for(int j = 0; j < loop; ++j) {
int sum = 0;
TEditBuffer::char_iterator itr = eb.char_begin();
TEditBuffer::char_iterator iend = eb.char_end();
for(int k = 0; itr != iend && k < N; ++itr, ++k)
sum += *itr;
}
cout << tm.elapsed() / loop * 1000 << "\n"; // 1000 for msec
}
}
// シーケンシャルアクセス+1文字削除時間計測
// 6文字進めて1文字削除を繰り返す
template< typename TEditBuffer, typename InputIterator >
void measure_seq_erase(InputIterator first, InputIterator last, int unit = 1000)
{
TEditBuffer eb;
InputIterator e = first;
const int beg = 2;
const int step = 2;
for(int i = beg; i <= 100; i += step) {
cout << i * unit << " ";
e = find_nth(e, last, '\n', unit * step);
eb.assign(first, e); // 構築
boost::timer tm;
TEditBuffer::char_iterator itr = eb.char_begin();
TEditBuffer::char_iterator iend = eb.char_end();
while( itr != iend ) {
for(int i = 0; i < 6 && itr != iend; ++i)
++itr;
if( itr == iend ) break;
itr = eb.erase(itr); // 1文字削除
iend = eb.char_end(); // 念のため
}
cout << tm.elapsed() << "\n";
}
}
// シーケンシャルアクセス+1文字挿入時間計測
// 7文字進めて1文字('#')挿入を繰り返す
template< typename TEditBuffer, typename InputIterator >
void measure_seq_insert(InputIterator first, InputIterator last, int unit = 1000)
{
TEditBuffer eb;
InputIterator e = first;
const int beg = 2;
const int step = 2;
for(int i = beg; i <= 100; i += step) {
cout << i * unit << " ";
e = find_nth(e, last, '\n', unit * step);
eb.assign(first, e); // 構築
boost::timer tm;
TEditBuffer::char_iterator itr = eb.char_begin();
TEditBuffer::char_iterator iend = eb.char_end();
while( itr != iend ) {
for(int i = 0; i < 7 && itr != iend; ++i)
++itr;
if( itr == iend ) break;
itr = eb.insert(itr, '#'); // 1文字挿入
++itr;
iend = eb.char_end();
}
cout << tm.elapsed() << "\n";
}
}
計測環境
各種データ構造
| vector<char> | (== string) 大量のテキストの場合:遅くてお話にならない |
| gap_vector<wchar_t> | 初期の Emacs (最近の版は不明) |
| list<wstring> | vi, 初期のViVi |
| gap_vector<string> | GreenPad |
| gap_vector<SLineItem> | ViVi 2.x |
| piece_table<char> | AbiWord |
| rope<char> | SGI STL |
gap_vector<wchar_t> は(初期の)Emacs のデータ構造、list<wstring> は(素の)vi のデータ構造。
最も単純なデータ構造のひとつ。
ランダムアクセスは O(1) だが、編集(挿入・削除・置換)処理は O(N)。 テキストエディタでは編集箇所が局所化されていることを利用したデータ構造。
(gap_vector 参照) 限界:メモリに入りきらないデータを取り扱うことは出来ない
行長が膨大になることは稀なので、1行を string (== vector<char>) で管理し、
行を双方向リンクで管理する。
行の挿入・削除処理は O(1) となる。 文字イテレータオブジェクトは行イテレータをメンバ変数に持ち、インクリメント・デクリメントで境界チェックを行い、文字イテレータを更新する。
欠点:行長が長い(1行100万文字とか)と、レスポンスが悪くなる(→ ViVi 2.x デモ)。 欠点:行数が膨大な場合、無駄なメモリ(ポインタ*2、メモリ管理のための領域)を大量に消費し、
new, delete が非常に遅くなる。 テキストデータを外部記憶に置くことで、メインメモリに入りきらないファイルも編集できなくは無い。
バッファクラスは gap_vector<wchar_t> オブジェクトをメンバ変数にもつ。 assign() は、gap_vector<wchar_t> の assign() をそのままコールする。
文字イテレータは gap_vector<wchar_t>::iterator をそのまま用いる。
編集メソッドは gap_vector<wchar_t> の編集メソッドをそのままコールする。
文字数は gap_vector<wchar_t>::size() をそのまま利用。 行数カウント:
編集時に行数更新を行う場合:
バッファクラスは list<wstring> オブジェクトをメンバ変数にもつ。
assign() は、行ごとに切り分け、それを push_back() で行追加を行う。
文字イテレータは list<wstring>::iterator をメンバ変数に持ち、wstring::iterator をラップする。
最初の版:
パフォーマンスチューニング版:
編集メソッドは基本的に wstring の編集メソッドをコールするが、改行を意識した処理が必要となる。
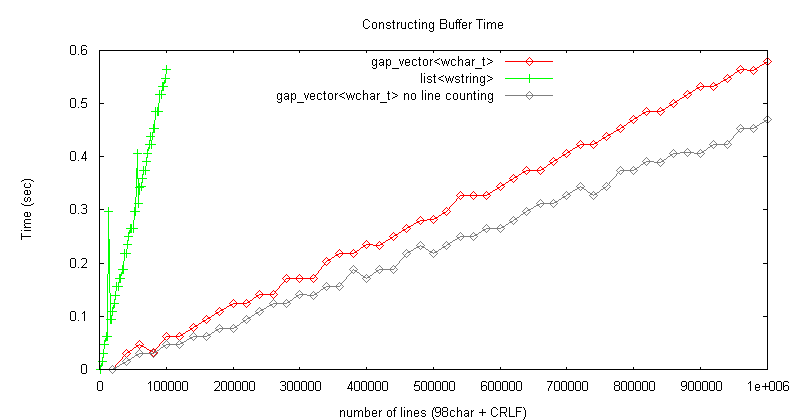
文字数情報はメンバ変数に保持し、編集メソッドで更新する。 下図に、Unicode (98文字 + CRLF) * 2千〜100万行のシーケンシャルデータでバッファを構築する時間、消費メモリ量測定結果を示す(測定プログラムは ここ を参照)。
構築時間は gap_vector<wchar_t> が list<wstring> より約10倍高速、
消費メモリ量は後者が前者より約50%多いメモリを消費 list<wstring> が遅く、メモリを浪費する原因:
(測定プログラムは ここ を参照)
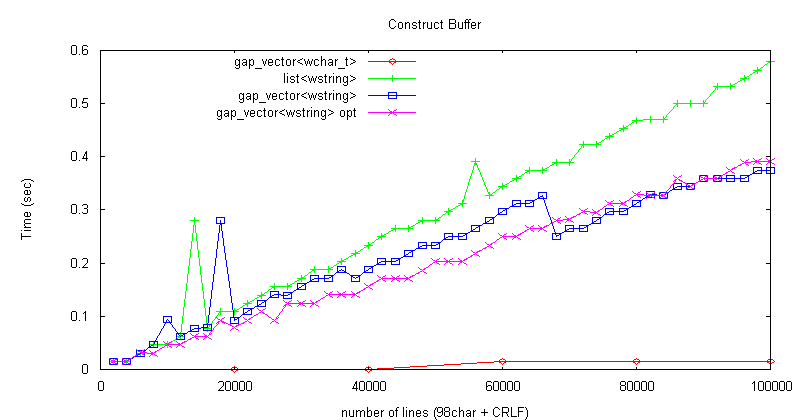
測定結果は上図の通り。 シーケンシャルアクセスは、抽象的なポインタを進める処理と、
そのブロックが終了した時に次のブロックに進む処理の2つから成る。 下図に、Unicode (98文字 + CRLF) * 2千〜10万行のデータについて、先頭から6文字進めて1文字削除をバッファ最後まで繰り返した場合の測定結果を示す。 次に削除処理自体の処理速度を見るために、先頭から5文字進めて2文字削除をバッファ最後まで繰り返した場合を測定した結果を以下に示す。 下図に、Unicode (98文字 + CRLF) * 2千〜10万行のデータについて、先頭から7文字進めて '#' を1文字挿入をバッファ最後まで繰り返した場合の測定結果を示す。 単純な list<wstring> では、どう贔屓目に見ても gap_vector<wchar_t> の性能(処理速度・メモリ効率)にはかなわないように見える。 それでもやっぱり vi が好き!
list はメモリ消費が大きいので、コンテナを gap_vector に交換。
list<wstring> メンバ変数の std::list を gap_vector に変更するだけ。他は同一。
構築時間は約30%高速化した(0.563 → 0.39)が、メモリ使用量は期待に反して単純には削減されていない。 そこで、下記の様にあらかじめ行数を計算し、reserve してからバッファを構築するようにしてみた。
行数計算の分遅くなるが、バッファ拡張時のコピー処理が無くなるので、相殺されて処理時間はほぼ同じだった。 シーケンシャルアクセス時間計測結果を下図に示す。 削除・挿入処理は list<wstring> と同じなので省略する。
list を gap_vector に変更すると、速度・メモリ効率が若干改善される。 STLシーケンスコンテナに準じたバッファインタフェースを定義し、gap_vector<wchar_t>, list<wstring>, gap_vector<wstring> を用いたバッファクラスを VC9 で実装し、パフォーマンス計測を行った。
一部分、パフォーマンスチューニングを行い、再計測を行った。 次稿では、list<wstring> の性能向上と piece_table について述べる予定。
gap_vector<wchar_t> VS. list<wstring>
データ構造概要
vector<char> (== string)

一括構築(assign)は高速で無駄なメモリ領域を発生させない。
欠点:特に大量のテキストがあるとき、先頭付近での挿入・削除は大量のデータの移動を伴うため
非常に遅い。
(gap_vector 参照)
末尾への挿入は O(1) だが、容量が足りなくなった場合、メモリをリアロケートし、データをコピーする必要がある。
同一サイズの置換はデータを書き換えるだけなので高速
gap_vector<wchar_t>

vector に比べ、安定的に優れたパフォーマンスを発揮する。
ランダムアクセスは O(1) で、編集(挿入・削除・置換)処理もおおむね O(1)
list に比べ、使用メモリ量が少ない。
編集処理のたびに行数更新処理が必要。コードが少し煩雑になる?
処理を行単位に記述したい場合、そのつど行の切り分け処理が必要になる。
→ 行イテレータを実装しておけば おk
list<wstring>

行番号を指標に行をランダムアクセスすることは出来ない(無理やり行うと O(N))が、通常はシーケンシャルアクセスで充分。
(ランダムアクセス的にプログラムを記述したい場合、
行番号キャッシュ法 が有効)
→ メモリ管理部分・処理速度に関する解決方法:boost::pool または同等機構(ViVi で採用)
実装
gap_vector<wchar_t>
(gap_vector<wchar_t> の実装は gap_vector で使った簡易的実装によるもの)
行数は必要になったときに数える or 行数を保持し、編集のたびに更新する。
// CRLF/CR/LF で行を区切る関数
template
// 1文字削除時の行数更新
template<typename InputIterator>
void update_line_size_at_erase(size_t &line_size,
size_t char_size,
const InputIterator &itr,
const InputIterator &cibegin,
const InputIterator &ciend)
{
InputIterator i2(itr);
InputIterator iend2(ciend);
switch( *itr ) {
case '\n':
// 直前が \r でなければ --行数
if( itr == cibegin || *--i2 != '\r' && --iend2 != itr )
--line_size;
break;
case '\r':
// バッファは \r のみ または 次が \n でなければ --行数
if( ++i2 != ciend && *i2 != '\n' || char_size == 1 )
--line_size;
break;
default:
// バッファは \r のみ または 最終文字でその前が改行
if( char_size == 1 || --iend2 == itr && (*--i2 == '\n' || *i2 == '\r') )
--line_size;
break;
}
}
// 1文字挿入時の行数更新
template<typename InputIterator, typename CharType>
void update_line_size_at_insert(size_t &line_size,
bool empty,
CharType ch,
const InputIterator &itr,
const InputIterator &cibegin,
const InputIterator &ciend)
{
InputIterator i2(itr);
switch( ch ) {
case '\n':
// 直前が \r で無ければ(バッファが空の場合はここに含まれる) ++行数、
// ただし itr がバッファ末尾の場合、その前が改行でない限り ++行数 しない
if( itr == cibegin || *--i2 != '\r' && (itr != ciend || *i2 == '\n') )
++line_size;
break;
case '\r':
// バッファが空 または 直後が \n で無ければ ++行数
if( empty || itr != ciend && *itr != '\n' )
++line_size;
break;
default:
// バッファが空 または バッファ末尾挿入で、直前が改行の場合は ++行数
if( empty || itr == ciend && (*--i2 == '\n' || *i2 == '\r') )
++line_size;
break;
}
}
class edit_buffer
{
size_t m_line_size; // 行数
.....
// itr 位置の文字を削除し、その次の文字へのイテレータを返す
char_iterator erase(char_iterator itr)
{
char_iterator ciend = char_end();
if( itr == ciend ) return itr;
update_line_size_at_erase(m_line_size, char_size(), itr, char_begin(), ciend);
return char_iterator(m_buffer.erase(itr.m_itr));
}
// itr 位置直前に文字を挿入し、その文字へのイテレータを返す
char_iterator insert(char_iterator itr, CharType ch)
{
update_line_size_at_insert(m_line_size, empty(), ch, itr, char_begin(), char_end());
return char_iterator(m_buffer.insert(itr.m_itr, ch));
}
};
list<wstring>
class char_iterator : public std::iterator<std::bidirectional_iterator_tag, CharType>
{
typename tstring::iterator m_itr; // 文字イテレータ
typename tstring::iterator m_iend; // 文字イテレータ
typename ContainerIterator m_litr; // 行イテレータ
edit_buffer_li_str *m_p; // 親コンテナへのイテレータ
.....
};
class char_iterator : public std::iterator<std::bidirectional_iterator_tag, CharType>
{
const CharType *m_itr; // 文字イテレータ
const CharType *m_iend; // 最終文字イテレータ
typename ContainerIterator m_litr; // 行イテレータ
edit_buffer_li_str *m_p; // 親コンテナへのイテレータ
.....
};
行数は list<wstring>::size() を利用する。
計測結果
バッファ構築時間・消費メモリ
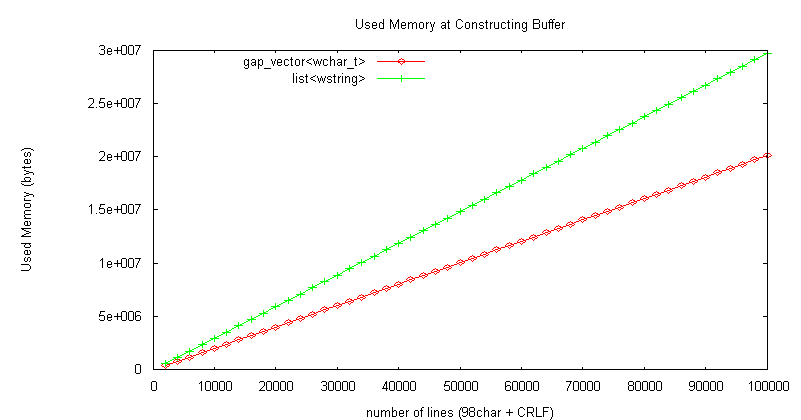
(10万行(== 1千万文字)構築時消費メモリ 前者:20,135,936 byte、後者:29,691,904 byte)、
という結果になった。
(C++は大量回数のメモリアロケートが遅い。ついでに言うと破棄も遅い)
シーケンシャルアクセス
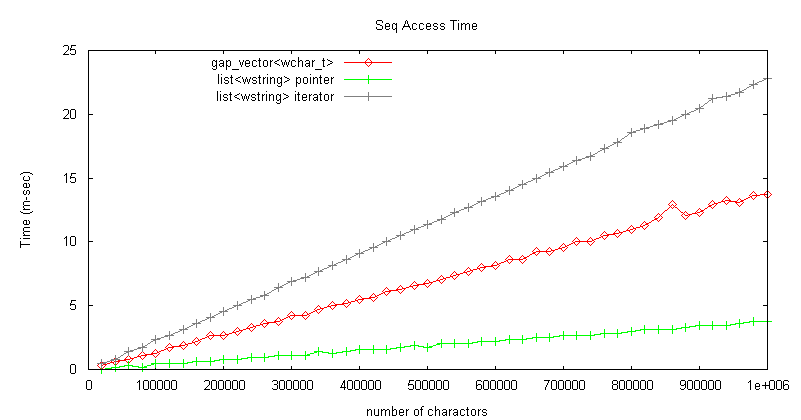
当初、list
gap_vector は後者の処理は必要ないが、現在の版では抽象的なポインタを進めるとき、
バッファの終わりとギャップ位置かどうかの判定を行っており、それが速度低下の原因と考えられる。
削除処理
gap_vector<wchar_t>, list<wstring> の処理速度は大差なく、どちらも約0.25秒/10万行であった。
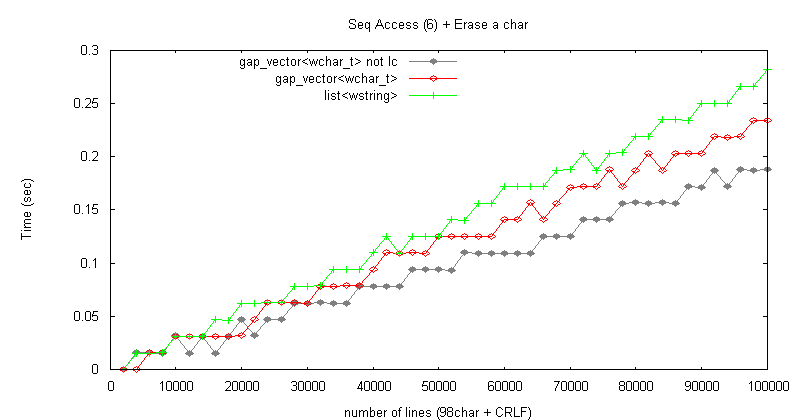
gap_vector<wchar_t> は1文字削除とほとんど処理時間が変わらないが、list<wstring> は約2倍の処理時間を要した。

挿入処理
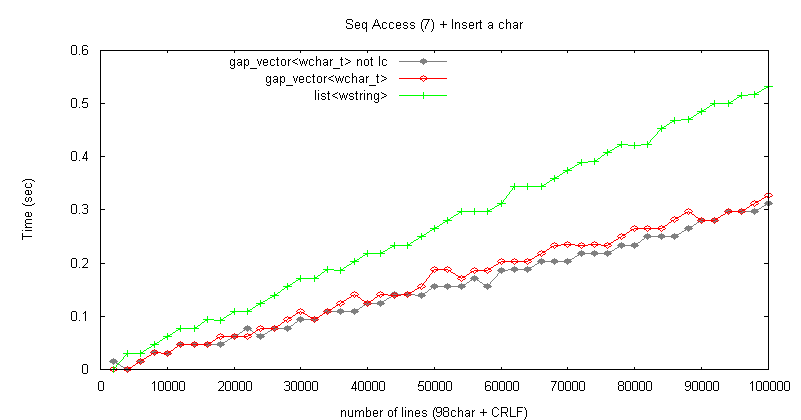

結論
gap_vector<wstring>
データ構造概要
実装
計測結果
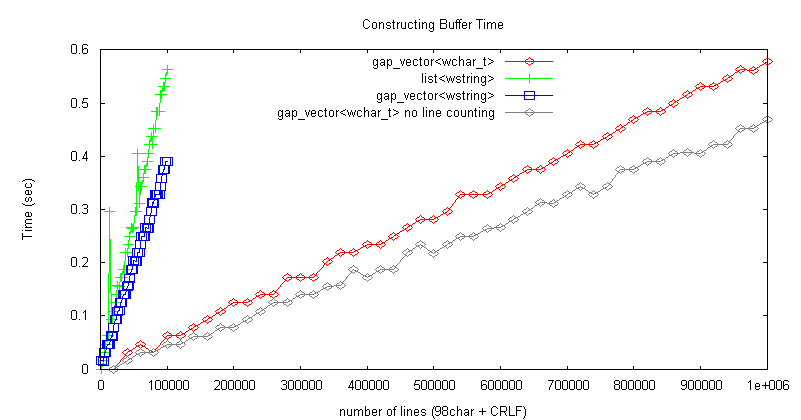
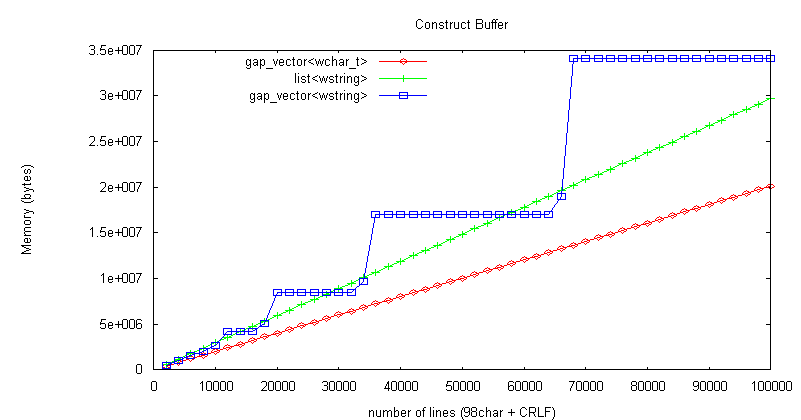
メモリ使用量が階段状なのは、行オブジェクトを1行ずつ追加しているため。
class edit_buffer
{
.....
template<typename InputIterator>
void assign(InputIterator first, InputIterator last)
{
m_size = last - first;
m_buffer.clear();
while( first != last ) {
InputIterator next = get_next_line(first, last);
m_buffer.push_back(tstring(first, next)tr);
first = next;
}
}
.....
}
class edit_buffer
{
.....
template<typename InputIterator>
void assign(InputIterator first, InputIterator last)
{
m_size = last - first;
m_buffer.clear();
m_buffer.reserve(get_line_count(first, last)); // 行数分の要素をリザーブ
while( first != last ) {
InputIterator next = get_next_line(first, last);
m_buffer.push_back(tstring(first, next)tr);
first = next;
}
}
.....
}
使用メモリは以下のように、前後へのリンクの分だけ減った。
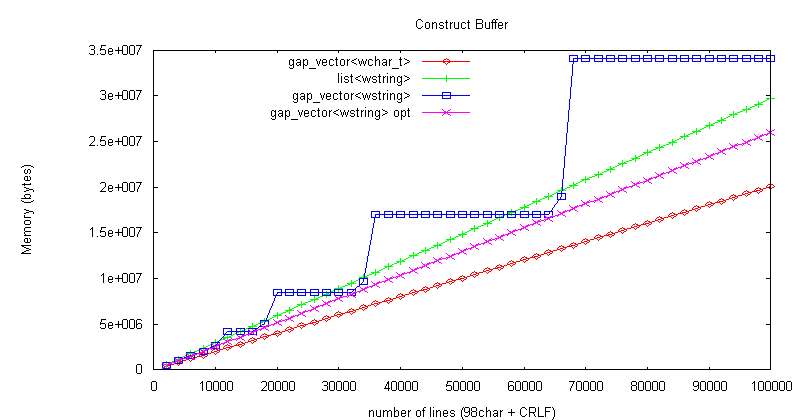
次の行要素に移動する頻度は少なく、list と gap_vector であまり差がないので、
シーケンシャルアクセス速度は list<wstring> と同等だった。
結論
行番号で行をランダムアクセスできるという利点もある。
終わりに
本稿の実装・比較項目では gap_vector<wchar_t> が速度、メモリ効率ともに優れていると認めざるを得ない。
参考文献